본문
5. AI 금융 모델 학습 완벽 가이드
Part 1. 준비 단계
허깅페이스 토큰 생성하기
Huggingface Access Tokens 생성 (계정 인증을 위한 토큰)
- https://huggingface.co > 로그인 > 우측 상단의 프로필 클릭 > "Settings" 선택
- 좌측 메뉴에서 "Access Tokens" 선택 > "New token" 클릭

- 토큰 이름 입력 및 권한 선택
- Token name: 용도를 알 수 있는 이름 설정 (예: sagemaker-training)
- Role: 필요한 권한 선택
- Read: 모델과 데이터셋 다운로드만 필요할 때 (default option)
- Write: 모델 업로드도 필요할 때
- 토큰값은 외부에 노출되지 않도록 주의
- 필요한 최소한의 권한만 부여

p.s. 환경 변수 설정 예시
environment = {
'TORCH_CUDA_ARCH_LIST': '7.0 7.5 8.0+PTX',
'TOKENIZERS_PARALLELISM': 'false',
'TRANSFORMERS_CACHE': '/tmp/transformers_cache',
'HF_HOME': '/tmp/huggingface',
'HUGGING_FACE_HUB_TOKEN': 'hf_생성된토큰값',
# 온라인 모드로 변경
'TRANSFORMERS_OFFLINE': '0',
'HF_HUB_OFFLINE': '0',
# 기타 설정
'PIP_PACKAGE_INSTALL': 'True',
'PYTHONPATH': '/opt/ml/code',
'PIP_NO_CACHE_DIR': 'True',
'PYTORCH_CUDA_ALLOC_CONF': 'max_split_size_mb:512',
}Part 2. 학습 환경 설정하기
1. 학습 특징
- 단계적 접근
- 기초 → 심화 순서로 진행
- 안정적인 학습을 위해 속도 조절
- 효율적인 학습
- 메모리 사용 최적화
- 여러 GPU로 분산 처리
- 효율적인 LoRA 방식 사용
- 데이터 관리
- Qwen2 형식으로 통일
- 적절한 길이로 조정
- 효율적인 데이터 처리 방식 적용
2. 프로젝트 구성
- 파일 구조와 역할
project_root/
├── sagemaker_train.ipynb # 학습 설정용 노트북
├── scripts/ # 실제 학습 파일들
├── train.py # 학습 실행 코드
├── tokenization_qwen2.py # 텍스트 처리기
├── requirements.txt # 필요 라이브러리 목록
└── bootstrap.sh # 환경 설정 스크립트
3. 작업 공간 이해하기
3-1 모델 개발을 위한 JupyterLab 노트북 환경 준비
- 용도: 학습 작업 설정 및 모니터링
- 사양: ml.g4dn.xlarge (비용 효율적 버전)
- 주요 파일
- 학습 환경 준비: sagemaker_train.ipynb
3-2 Training Job 실행을 위한 학습용 서버 환경 구성
- 용도: 실제 AI 모델 학습 수행
- 사양: ml.p5.48xlarge (고성능)
- 주요 파일
- 학습 로직: train.py
- 텍스트 변환 처리: tokenization_qwen2.py
- 기타 학습 최적화 설정 파일들: requirements, bootstrap.sh

3-3 JupyterLab 환경 설정

a) 인스턴스 선택
- 유형: ml.g4dn.xlarge
- 저장 공간: 100GB (권장)
b) 가상 환경 설정 (terminal)
python -m ipykernel install --user --name=test_venv
- ipykernel 커널 생성

- 생성한 커널로 변경 (ipykernel -> test_venv)

c) 필요 라이브러리 설치
pip install transformers datasets torch accelerate requests
- transformers (AI 모델들의 집합소)
- Transformers 라이브러리를 통해 허깅페이스에 있는 다양한 AI 모델들을 쉽게 다운로드하고 사용할 수 있습니다.
- 마치 레고 블록처럼 미리 만들어진 AI 모델들을 가져다 사용할 수 있어요
- 예시: GPT로 글쓰기, BERT로 문장 이해하기 등
- datasets (AI 학습을 위한 데이터 관리공간)
- Hugging Face에서 제공하는 데이터셋 라이브러리로, AI 학습에 필요한 다양한 데이터를 쉽게 다운로드하고 관리할 수 있습니다.
- 대용량 데이터도 메모리 걱정 없이 효율적으로 처리할 수 있어요
- 예시: NSMC(한국어 영화 리뷰), klue(한국어 자연어 처리) 등의 데이터셋을 쉽게 불러와서 사용
- torch (AI 모델의 기초 프레임워크)
- Meta(구 Facebook)에서 만든 딥러닝 프레임워크로, AI 모델을 만들고 학습시키는 기본 도구입니다.
- 파이썬에서 쉽게 사용할 수 있고, GPU를 활용한 빠른 연산이 가능해요
- 예시: 신경망 층 만들기, 손실 함수 정의, 역전파 학습 등 AI 모델의 핵심 기능 제공
- accelerate (분산 학습 도우미)
- Hugging Face에서 만든 도구로, 복잡한 분산 학습 설정을 간단하게 만들어줍니다.
- 단일 GPU, 다중 GPU, TPU 등 다양한 환경에서 코드 수정 없이 학습이 가능해요
- 예시: 8개의 GPU를 사용한 학습, CPU와 GPU 메모리 최적화 등
- requests (웹 통신 도구)
- 파이썬에서 HTTP 통신을 쉽게 할 수 있게 해주는 라이브러리입니다.
- 인터넷을 통해 데이터를 주고받을 때 사용하며, API 호출도 간단하게 할 수 있어요
- 예시: 모델 파일 다운로드, REST API 호출, 웹 크롤링 등
Part 3. 메모리 최적화와 분산 학습 설계
1. 메모리 최적화

a. 4비트 양자화
- 실생활 비유
- 개발 원본: 4K 영상 (100MB)
- 배포 버전: HD 영상 (50MB) - 허깅페이스에서 다운로드되는 버전
- 학습용 버전: 압축 영상 (12.5MB) - 4비트 양자화 후
- 메모리 사용량 예시
- 모델 원본(32비트) = 28GB
- 배포 버전(16비트) = 허깅페이스에서 다운로드 (14GB)
- 학습용 버전: 4비트 양자화 (약 3.5GB)
b. 그래디언트 체크포인팅(Gradient Checkpointing)
AI 모델 학습 시 모든 과정을 기억하면 메모리가 부족해집니다. 체크포인팅은 중요한 부분만 저장하고 필요할 때 다시 계산하는 방식으로, 메모리를 크게 절약할 수 있게 해주죠.
- 일반적인 AI 학습 방식:
- 등산할 때 모든 지점을 사진 찍어두는 것과 같음
- 하산할 때 모든 사진을 다시 봐야 함
- 사진이 너무 많아서 메모리(공간)가 부족해짐
- 체크포인팅 사용 시:
- 중요한 지점만 사진 찍어두기
- 필요할 때 그 구간을 다시 걸어가면서 확인
- 사진(메모리) 저장 공간을 크게 절약
- 결과적으로:
- 메모리 사용량 60-70% 절감
- 대신 일부 구간을 다시 계산해야 해서 속도는 약간 느려짐
- 더 큰 AI 모델을 학습할 수 있게 됨
c. LoRA 파라미터 설정
LoRA(Low-Rank Adaptation)는 기존 AI 모델의 전체 파라미터를 직접 수정하지 않고, 적은 수의 파라미터만을 사용하여 모델을 새로운 태스크에 적응시키는 방법입니다.
- 메모리 효율
- 수백 GB → 수십 MB
- 빠른 학습
- 일부분만 수정
- 유연한 관리
- 필요할 때만 적용
- 여러 버전 관리 용이
👀 메모리 사용량 분석
GPU 메모리(VRAM) 28GB가 필요한 AI 모델을 4비트 양자화, 그래디언트 체크포인팅, LoRA 기술을 활용해 4.5GB까지 최적화하여 학습합니다.
[기본 모델] → 28GB/GPU
[4비트 양자화 적용] → 7GB/GPU (-75%)
[그래디언트 체크포인팅] → 4.2GB/GPU (-40%)
[LoRA 적용] → 4.5GB/GPU (학습 파라미터만 증가)
# 1. 4비트 양자화 설정 (메모리 75% 절감)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # FP16 대비 75% 메모리 절감
bnb_4bit_use_double_quant=True, # 추가 10% 메모리 절감
bnb_4bit_compute_dtype=torch.bfloat16 # 학습 안정성 향상
)
# 2. 그래디언트 체크포인팅 (메모리 40% 추가 절감)
training_args = TrainingArguments(
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# 3. LoRA 설정 (학습 파라미터 99% 감소)
lora_config = LoraConfig(
r=16, # 적응 순위 (rank)
lora_alpha=32, # 스케일링 파라미터
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 학습 대상 모듈
lora_dropout=0.05 # 오버피팅 방지
)
2. 분산 학습 구성
예시: 8개의 GPU를 사용하여 학습하되, 2개씩 짝지어 4개의 데이터 샤드를 처리

- FSDP(Fully Sharded Data Parallel)모델의 파라미터를 여러 GPU에 나누어 저장하고(sharding), 필요할 때마다 통신하여 사용하는 방식
- 퍼즐을 여러 조각으로 나눠서 분배
- 각자 맡은 부분만 집중해서 작업
- 필요할 때 서로 정보 공유
environment = { # 모델 나누기 설정 'FSDP_AUTO_WRAP_POLICY': 'TRANSFORMER_BASED_WRAP', # 메모리 효율화 설정 'FSDP_BACKWARD_PREFETCH': 'BACKWARD_POST', # 모델 저장 방식 'FSDP_STATE_DICT_TYPE': 'FULL_STATE_DICT', # GPU 설정 'CUDA_VISIBLE_DEVICES': '0,1,2,3,4,5,6,7', 'PYTORCH_CUDA_ALLOC_CONF': 'max_split_size_mb:512' }- 모델의 파라미터를 여러 GPU에 나누어 저장하고(sharding), 필요할 때마다 통신하여 사용하는 방식
- 특장점
- 메모리 절약
- GPU당 필요한 메모리 크게 감소
- 더 큰 모델 학습 가능
- 효율성 향상
- 작업 부하 균등 분배
- GPU 자원 최대한 활용
- 확장성
- GPU 추가가 쉬움
- 더 많은 GPU로 더 빠른 학습
- 메모리 절약
- 학습 소요 시간 예시
- 데이터셋 크기: 1M 샘플 기준
- 8 GPU: 약 17분 소요
- 단일 GPU: 약 2시간 20분 소요
- 데이터셋 크기: 1M 샘플 기준
Part 4. 단계별 학습 프로세스
1. 기초 금융 지식 학습
Qwen 2.5-7B-Instruct 모델을 Finance Alpaca 데이터셋으로 LoRA 파인튜닝을 합니다.
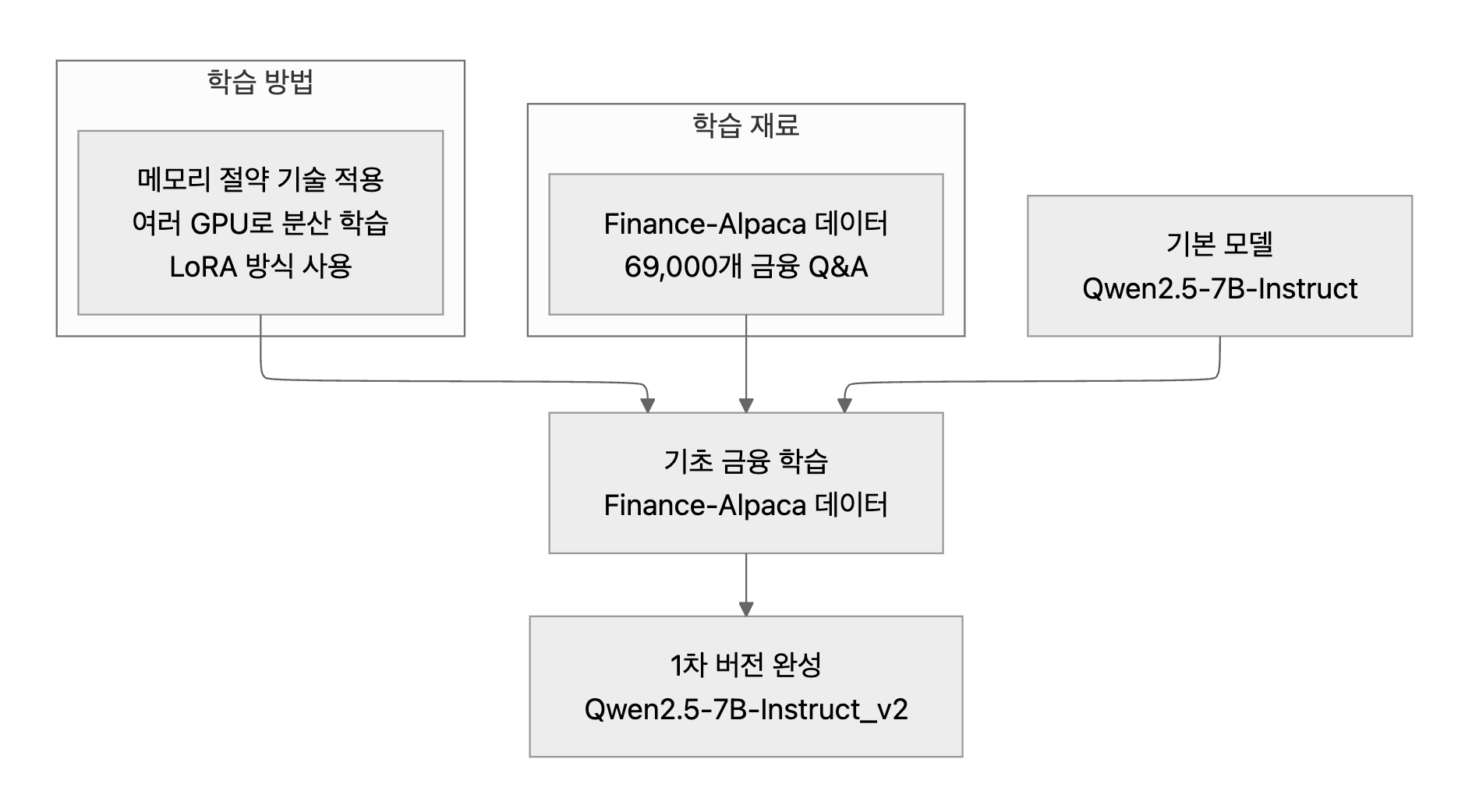
- 📜 소스 코드
- 데이터셋
- Finance-Alpaca 데이터 활용
- 69,000개 Q&A 학습
- 소스코드 핵심 기능
- 환경 설정과 점검 (check_environment):
- PyTorch, CUDA, GPU 상태 체크
- 시스템 리소스 정보 로깅
- 모델과 토크나이저 설정 (load_model_and_tokenizer):
- 4비트 양자화로 메모리 효율적 로드
- LoRA 설정 (r=16, alpha=32)
- 주요 타겟 레이어: q_proj, k_proj, v_proj, o_proj
- 단일/분산 학습 환경 자동 감지
- 데이터셋 준비 (prepare_dataset):
- Finance Alpaca 데이터셋 로드
- Qwen2 형식에 맞게 대화 포맷팅
- 2048 토큰 길이로 패딩
- 학습 설정 (train_model):
- bfloat16 정밀도
- Cosine 러닝레이트 스케줄링
- 그래디언트 체크포인팅
- 분산 학습 최적화
- 환경 설정과 점검 (check_environment):
- 결과 예시

2. 심화 금융 지식 추가
1차 학습된 모델을 Sujet-Finance 데이터셋을 활용하여 추가 파인튜닝을 진행합니다.

- 📜 소스 코드
- 데이터셋
- Sujet-Finance 데이터 적용
- 177,000개 Q&A 추가 학습
- 소스코드 핵심 기능
- 데이터셋 준비 (prepare_dataset):
- Sujet Finance 데이터셋 로드
- Qwen2 형식으로 대화 데이터 포맷팅
- 토큰화 및 패딩 처리
- 모델 & 토크나이저 로드 (load_model_and_tokenizer):
- 4비트 양자화 설정으로 베이스 모델 로드
- 기존 학습된 LoRA 어댑터 로드
- GPU 디바이스 매핑
- 모델 로드 소스코드: Base Model + 1차 학습 모델
- 모델 훈련 (train_model):
- 학습 파라미터 설정 (배치 사이즈, 학습률 등)
- HuggingFace Trainer로 학습 진행
- 모델 저장 및 메트릭 기록
- 데이터셋 준비 (prepare_dataset):
- 특징
- 4비트 양자화로 메모리 효율적 학습
- 기존 LoRA 모델 이어서 학습 가능
- 그래디언트 체크포인팅으로 메모리 최적화
- 분산 학습 지원 (DDP)
p.s. 모델 & 토크나이저 로드 (load_model_and_tokenizer):
- 모델 로드 소스코드: Base Model + 1차 학습 모델
def load_model_and_tokenizer():
"""모델과 토크나이저 로드"""
try:
base_model_id = os.environ.get("MODEL_ID", "Qwen/Qwen2.5-7B-Instruct")
peft_model_id = "seong67360/Qwen2.5-7B-Instruct_v2" # 기존 학습된 LoRA 모델
hf_token = os.environ.get("HF_TOKEN")
...
# 기본 모델 로드
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
token=hf_token,
trust_remote_code=True,
quantization_config=bnb_config,
device_map={"": local_rank},
torch_dtype=torch.bfloat16,
use_cache=False
)
base_model = prepare_model_for_kbit_training(base_model)
# 기존 LoRA 어댑터 로드
model = PeftModel.from_pretrained(
base_model,
peft_model_id,
token=hf_token,
is_trainable=True,
device_map={"": local_rank} # LoRA 모델에도 device_map 설정 추가
)
model.print_trainable_parameters()
logger.info(f"Model device: {next(model.parameters()).device}")
return model, tokenizer
3. 모델 병합
대규모 언어 모델을 파인튜닝한 후, 어댑터 모델과 베이스 모델을 하나로 병합하는 과정을 자동화합니다.
- 📜 소스 코드
- 핵심 기능
- S3에서 학습된 adapter 모델을 다운로드
- Qwen 2.5-7B-Instruct 베이스 모델을 로드
- adapter와 베이스 모델을 병합
- 병합된 모델을 저장
- 결과 예시
최종 모델 = 기본 모델(Qwen2.5-7B-Instruct) + 기초 학습(Finance-Alpaca) + 심화 학습(Sujet-Finance)

Part 5. 학습 결과 확인
1. 학습 진행 상황 확인
SageMaker Studio → Jobs → Training → (학습 이력 선택) → Logs
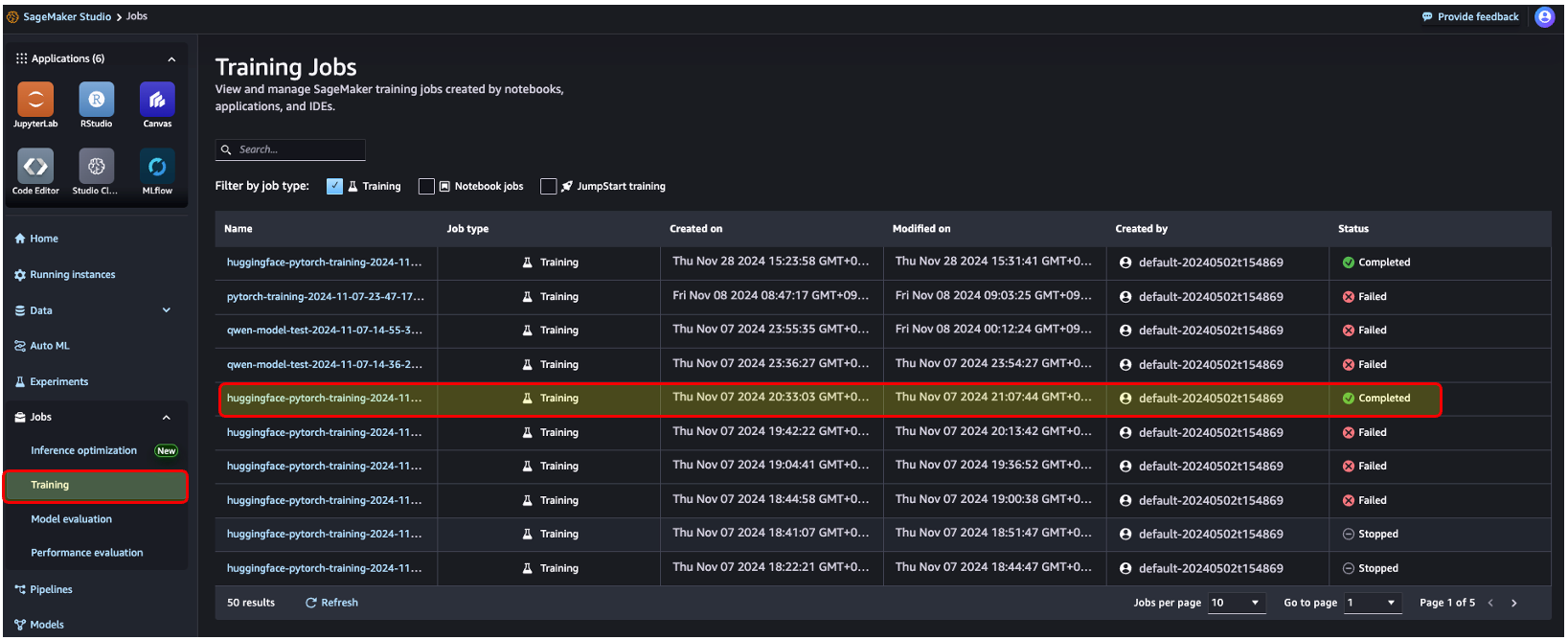


2. 모델학습 결과 확인
SageMaker Studio → Jobs → Training → (학습 이력 선택) → Logs

3. 산출물 경로 확인
SageMaker Studio → Jobs → Training → (학습 이력 선택) → Artifacts
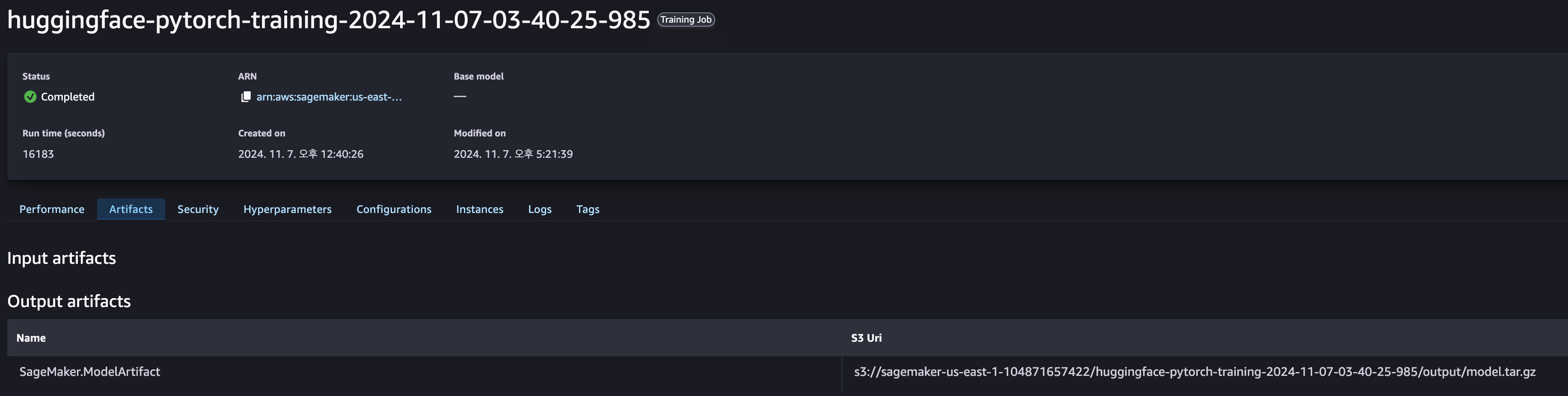
4. 산출물 확인
S3 → 버킷 이름 검색 → Artifacts 경로 이동 및 확인



5. 산출물 예시
tar.gz 파일을 압축 해제하면 다음과 같은 파일들이 생성됩니다.
- 어댑터 모델 결과 예시
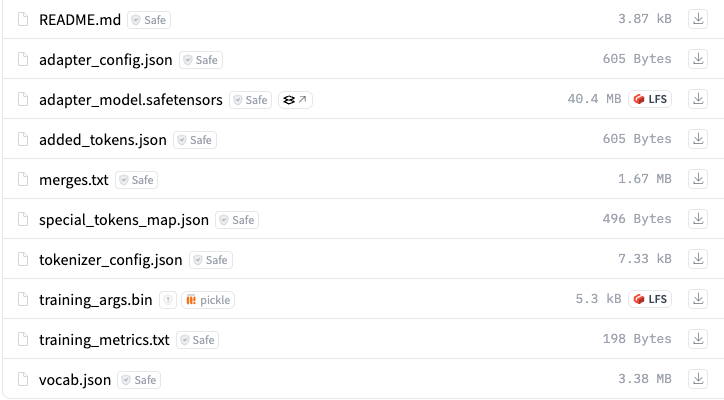
- 최종 모델 결과 예시




댓글