본문
6. AI 검색을 더 똑똑하게: 문서 정리의 기술
AI&ML/파인튜닝 2025. 12. 17. 01:24
반응형
똑똑한 AI를 만드는 방법
사람의 정답을 답변하기 위한 전략

LLM의 정답을 답변하기 위한 전략
- 파인튜닝
- 프롬프트 엔지니어링
- RAG(검색 증강 생성)
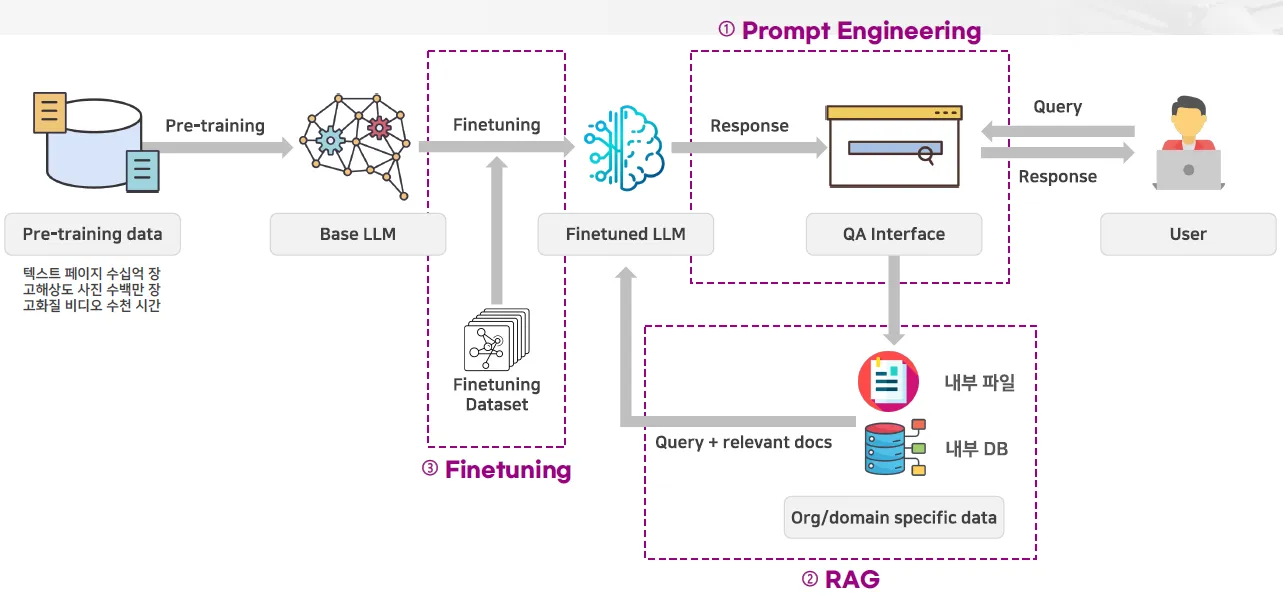
1. 프롬프트 엔지니어링
프롬프트는 AI에게 주는 지시나 질문입니다. 마치 학생에게 문제를 내듯이, 명확하게 질문할수록 좋은 답변을 받을 수 있습니다.
프롬프트:
- 단순 질문의 경우
- 나쁜 예: "커피에 대해 알려줘"
- 좋은 예: "아라비카 커피와 로부스타 커피의 차이점을 맛, 카페인 함량, 가격 측면에서 설명해줘"
- 요약을 요청할 때
- 나쁜 예: "이 글 요약해줘"
- 좋은 예: "이 글의 핵심 내용을 3개의 문장으로 요약하고, 각 요점에 번호를 붙여줘"
- 분석을 요청할 때
- 나쁜 예: "이 데이터 분석해줘"
- 좋은 예: "지난 6개월간의 매출 데이터를 월별로 분석하고, 성장률과 주요 변동 원인을 설명해줘
- 비교를 요청할 때
- 나쁜 예: "이것들 비교해줘"
- 좋은 예: "전기차와 수소차의 장단점을 환경영향, 충전 시간, 유지비용 측면에서 표로 만들어 비교해줘"
프롬프트 작성 팁:
- 구체적인 형식 지정하기
- 답변 길이: "300자 이내로..."
- 형식: "표로 작성해줘", "번호를 붙여서..."
- 예시: "다음과 같은 형식으로 작성해줘..."
- 맥락 제공하기
- 대상: "고등학생이 이해할 수 있는 수준으로..."
- 목적: "회의 자료로 사용할 거야..."
- 상황: "전문가가 아닌 일반인에게 설명하듯이..."
페르소나 프롬프트
AI에게 특정 전문가나 역할을 부여하면, 해당 관점에서 더 전문적이고 맥락에 맞는 답변을 받을 수 있습니다.
- 전문가 역할 부여
- 나쁜 예: "주식 투자 방법 알려줘"
- 좋은 예: "당신은 20년 경력의 투자 전문가입니다. 초보 투자자를 위한 주식 투자 입문 가이드를 5가지 핵심 원칙으로 설명해주세요."
- 교육자 역할
- 나쁜 예: "광합성 설명해줘"
- 좋은 예: "당신은 중학교 과학 선생님입니다. 학생들이 쉽게 이해할 수 있도록 광합성 과정을 일상생활의 예시를 들어 설명해주세요."
- 특정 분야 전문가
- 나쁜 예: "이 코드 개선해줘"
- 좋은 예: "당신은 10년 차 Python 개발자입니다. 이 코드를 성능과 가독성 측면에서 검토하고, 개선사항을 구체적인 예시와 함께 제안해주세요."
페르소나 프롬프트 작성 팁:
- 전문성 수준 명시하기
- "당신은 15년 경력의 소아과 의사입니다..."
- "실리콘밸리에서 일하는 수석 개발자의 관점으로..."
- 목표 대상 지정하기
- "컴퓨터를 처음 사용하는 노인을 대상으로..."
- "5살 아이에게 설명하듯이..."
- 상황 설정하기
- "당신은 대형 서점의 베스트셀러 담당 MD입니다. 이번 달 추천 도서 목록을..."
- "유명 레스토랑의 수석 셰프로서, 이 레시피를 가정에서 쉽게 따라할 수 있도록..."
2. RAG
RAG 시스템의 이해
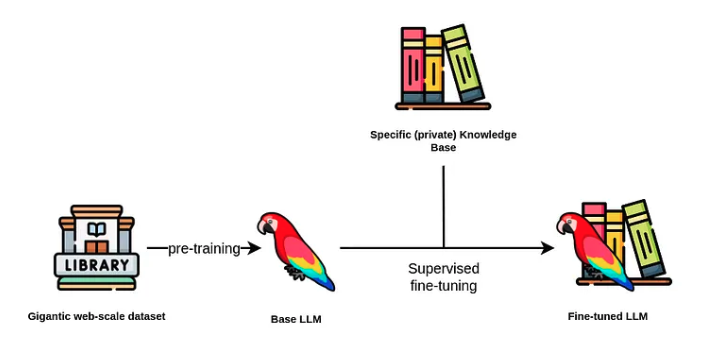
기본 개념
RAG(Retrieval-Augmented Generation)는 AI가 답변할 때 참고 자료를 찾아보고 답하는 방식입니다.
마치 학생이 시험 볼 때 교과서를 찾아보면서 답하는 것과 비슷합니다.
장점
- 최신 정보 반영 용이
- 신뢰성 높은 답변
- 답변 출처 추적 가능
RAG 시스템의 문서 처리 절차

- 원본 문서 입력
- PDF, Word, 텍스트 등의 문서를 시스템에 업로드
- 예: 금융 상품 설명서, 연간 보고서, FAQ 문서
- OCR이나 파싱을 통해 텍스트 추출
- 메타데이터(작성일, 출처 등) 추출
- PDF, Word, 텍스트 등의 문서를 시스템에 업로드
- 문서 분할 (청킹)
- 긴 문서를 적절한 크기로 나누기
- 예: 50페이지 문서를 1페이지씩 분할
- 토큰 수나 문자 수 기반으로 청크 크기 설정
- 문맥 유지를 위해 일부 내용은 중복(오버랩) 허용
- 긴 문서를 적절한 크기로 나누기
- 벡터화 (임베딩)
- 각 청크를 임베딩 모델로 벡터화(텍스트를 숫자로 변환)
- 예: "주식투자"라는 단어를 [0.2, 0.8, 0.5, ...]와 같은 숫자 배열로 변환
- 문맥을 고려한 의미 기반 벡터 생성
- 임베딩 모델 예: OpenAI 임베딩, BERT, Sentence Transformers
- 각 청크를 임베딩 모델로 벡터화(텍스트를 숫자로 변환)
- 인덱싱
- 빠른 검색을 위해 벡터에 인덱스 부여
- 벡터 데이터베이스에 색인 생성
- 유사도 검색을 위한 인덱스 구조 생성
- 예: 도서관의 책 분류 번호처럼 벡터에 고유 번호 부여
- 메타데이터와 벡터 데이터 연결
- 빠른 검색을 위해 벡터에 인덱스 부여
- 저장소 보관
- 벡터 데이터베이스에 벡터와 메타데이터 저장
- 금융 상품 설명서 처리 예시
{
"vector": [0.2, 0.8, 0.5, ...], # 임베딩된 벡터값
"text": "이 적금 상품의 기본금리는 연 3.5%이며, ...", # 원본 텍스트
"metadata": {
"document_id": "savings_product_2024", # 문서 ID
"page_number": 3, # 페이지 번호
"chunk_id": "chunk_127", # 청크 ID
"created_date": "2024-02-19", # 문서 작성일
"product_type": "savings", # 상품 유형
"last_updated": "2024-02-19" # 최종 업데이트일
}
}
반응형




댓글