본문
AWS 솔루션 아키텍트(SAA) 핵심 서비스 요약 정리
AWS/훑어보기 2025. 12. 17. 07:07
필자는 2025년 초 AWS Solutions Architect Associate를 취득했다.
실무에서 직접 운영하던 인프라 구성과 자격증 출제 범위가 상당 부분 겹쳐서, 공부하면서 실무 지식을 체계화하는 데 도움이 됐다.
아래는 실무에서 알아두면 좋은 내용을 선별하여 정리한 내용이다.
(필자 배경: 금융권 클라우드 서비스 개발/운영)

1. 스토리지 (Storage)
Storage Gateway
- 온프레미스 와 AWS 클라우드의 스토리지 연결 솔루션
- 온프레미스 로컬캐시 기능을 통해 자주 사용하는 데이터를 빠르게 액세스 가능
- 로컬캐시: 짧은 지연시간!
- ⚠️ 데이터 마이그레이션 솔루션 X


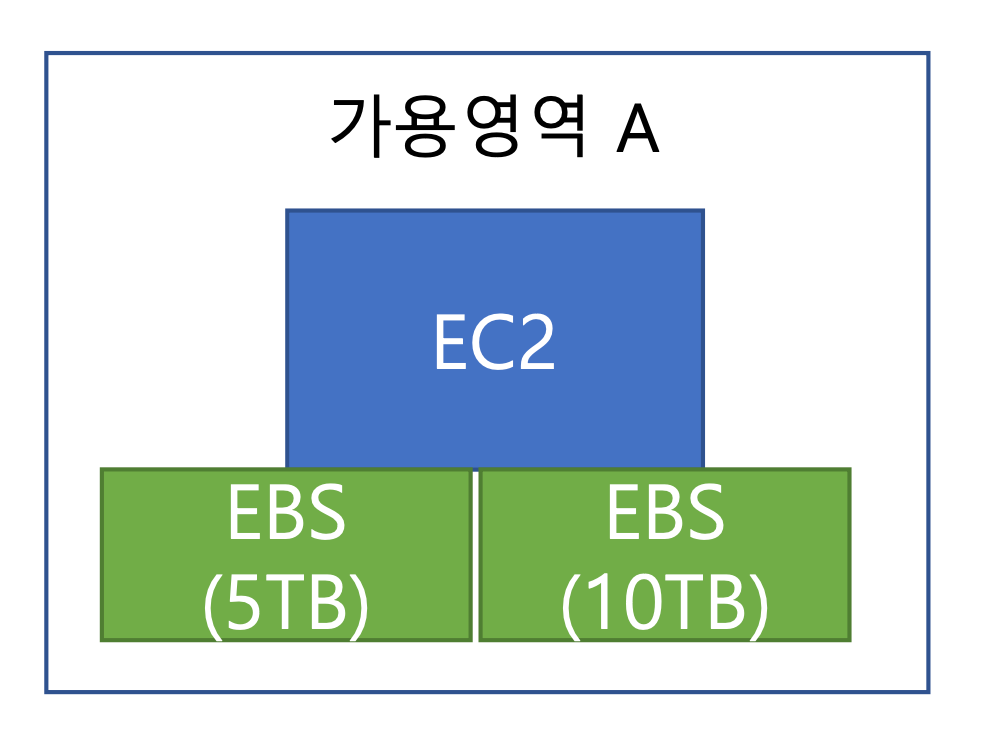
EBS (Elastic Block Store) #공유블록장치볼륨
- EC2 볼륨 스토리지
- 단일 가용영역의 EC2만 연결 가능!
- 확장성에 제한이 있음
- 동일 가용 영역, 단일 가영 영역
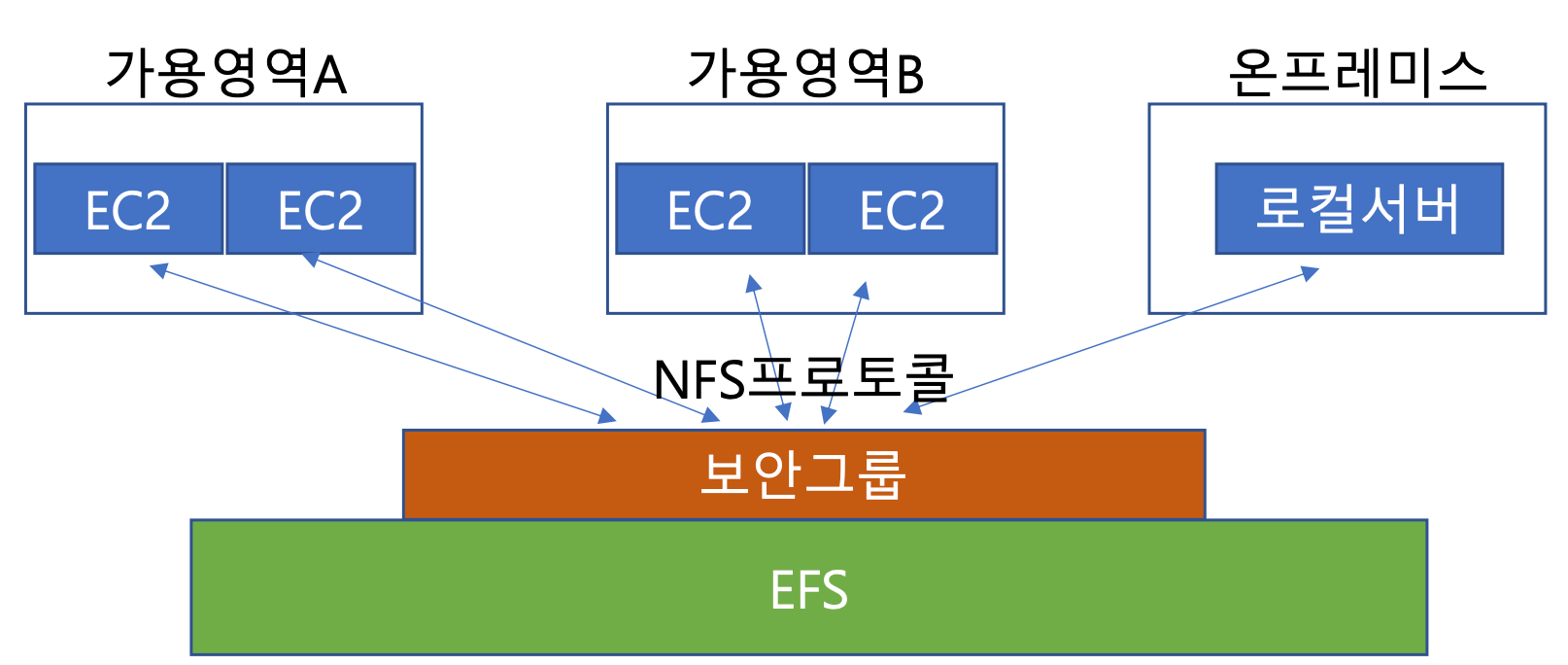
EFS (Elastic File System) #NFS #리눅스 #파일공유스토리지
- EC2용 관리형 파일 스토리지(for 리눅스)
- 확장성에 제한이 없다 ↔ EC2 EBS는 단일 가용 영역 인스턴스만 연결 가능
- 수십~수백 대의 EC2 연결 및 EC2 인스턴스 간에 데이터를 공유하는 고성능 솔루션
- 로컬캐시 기능을 지원하지 않음!
- NFS(Network File System) 파일 공유를 지원하는 스토리지 솔루션
↔ SMB 프로토콜: 윈도우(windows) OS 지원 (FSx 구성; SMB를 지원하는 완전관리형 파일공유 시스템)
Instance Store
- 블록 수준의 임시 스토리지
- Instance Store는 EC2 인스턴스가 종료되면 데이터가 삭제되므로 영구적인 저장소가 아닌 고성능을 요구하는 애플리케이션의 임시 저장소로 적합
- 초당 수백만 개의 트랜잭션을 지원하는 I/O 처리량이 높은 DB 데이터의 임시 스토리지 옵션으로 사용
- ex1) 여러 Amazon EC2 인스턴스에 분산 데이터베이스를 배포하고 있습니다. 데이터베이스는 인스턴스 손실을 견딜 수 있도록 모든 데이터를 여러 인스턴스에 저장합니다. 데이터베이스에는 서버 당 초당 수백 만개의 트랜잭션을 지원하기 위해 대기 시간 및 처리량이 있는 블록 스토리지가 필요합니다.
- 정답: Amazon EC2 인스턴스 스토어 (가장 고성능 임시 블록 스토리지, 인스턴스 손실을 견딜 수 있으므로 적합)
S3
- 거의 무제한 저장 공간 제공
- ⚠️ 제약사항
- HTTPS를 통해 S3로 바로 메시지 수신 불가
- S3에 SW를 바로 구현할 수 없음
- ex1) 새 문서 저장된 후에 수정/삭제할 수 없도록 해야함
- S3 버전 관리 및 S3 객체 잠금이 활성화된 Amazon S3 버킷에 저장
- ex2) 회사는 우발적인 삭제로부터 보호되기를 원합니다.
- 버전 관리 활성화
- MFA(Multi Factor Authentication; 다중 인증) 삭제 활성화
- ex3) 솔루션 설계자는 엔지니어링 도면을 저장하고 보는 데 사용되는 새로운 웹 애플리케이션 또는 스토리지 아키텍처를 설계하고 있습니다. 모든 애플리케이션 구성 요소는 AWS 인프라에 배포됩니다. 응용 프로그램 설계는 사용자가 엔지니어링 도면이 로드되기를 기다리는 시간을 최소화하기 위해 캐싱을 지원해야 합니다. 응용 프로그램은 페타바이트의 데이터를 저장할 수 있어야 합니다. 솔루션 설계자는 어떤 스토리지와 캐싱 조합을 사용해야 합니까?
- Amazon CloudFront를 사용하는 Amazon S3
- ex4) 데이터 과학 팀은 야간 로그 처리를 위한 스토리지가 필요합니다. 로그의 크기와 수는 알 수 없으며 24시간 동안만 유지됩니다. 가장 비용 효율적인 솔루션은 무엇입니까?
- Amazon S3 Glacier (X: 최소 과금 기간 90일)
- Amazon S3 표준 (정답: 최소 과금 기간 없음)
- Amazon Glacier Deep Archive (X: 최소 과금 기간 180일)
- Amazon S3 One Zone-Infrequent Access(S3 One Zone-IA) (X: 최소 과금 기간 30일)
- ex5) 회사는 웹사이트 호스팅에…EBS를 이용하고 있다. 솔루션 설계자는 회사가 애플리케이션 코드를 업데이트하거나 웹사이트를 조정하지 않고 이러한 요구 사항을 충족해야 합니다.
Amazon S3 버킷에 제품 설명서 저장 이 버킷으로 다운로드 리다이렉션- X: S3로 데이터를 저장하려면 애플리케이션 코드 변경 필요
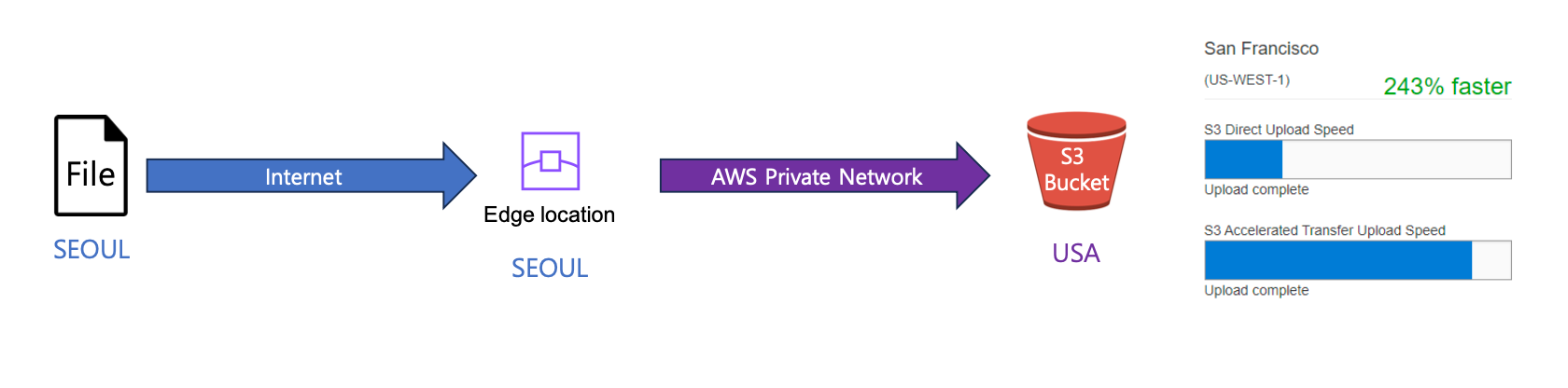
- S3 Transfer Acceleration
- S3 전송 가속화 솔루션
- 전 세계에 분산된 엣지 로케이션을 활용하여 최적화된 네트워크 경로를 통해 Amazon S3로 라우팅
- ex) 회사는 웹사이트를 통해 사진을 업로드할 수 있는 속도를 높이고자 합니다.
↔ CloudFront는 콘텐츠를 사용자에게 빠르게 배포하기 위한 솔루션
S3 CORS(Cross-Origin Resource Sharing)
- 다른 버킷에 대한 액세스를 공유/허용하는 기능
- 권한이 없는 사용자가 액세스하는 것을 방지할 수 있음

S3 Intelligent-Tiering
- 액세스 패턴을 모니터링하여 액세스 빈도가 낮은 객체는 자동으로 저렴한 계층으로 이동
- 액세스 패턴을 알 수 없거나, 액세스 패턴이 변화하는 데이터에 대한 스토리지 비용을 최적화하려는 경우에 사용
- S3 Standard-IA (Infrequent Access)
- 빈번하지 않은 액세스용
- 자주 액세스하지 않지만, 필요할 때 빠르게 액세스해야 하는 데이터에 적합
- 최소 과금 기간 30일
Lustre #HPC
- FSx for Lustre: 고성능 병렬처리, 고성능 컴퓨팅(HPC)를 위한 리눅스 파일
- 머신 러닝, 빅데이터 등의 고성능 컴퓨팅에 사용 (HPC; High Performance Computing)
- ex1) 고성능 컴퓨팅(HPC) 환경이 있고 예측 기능을 확장하고자 합니다. 대량의 지속적인 처리량을 처리할 수 있는 클라우드 스토리지 솔루션을 식별해야 합니다.
- ex2) 고성능 머신 러닝을 포함하는 회사의 애플리케이션을 위한 관리형 스토리지 솔루션을 설계해야 합니다… 연결된 스토리지는 파일에 동시에 액세스하고 고성능을 제공해야합니다.
- Amazon FSx for Lustre 파일 공유를 생성하고 Fargate가 FSx for Lustre와 통신할 수 있도록하는 IAM 역할을 설정합니다.
2. 네트워킹 및 콘텐츠 전송 (Networking & Content Delivery)
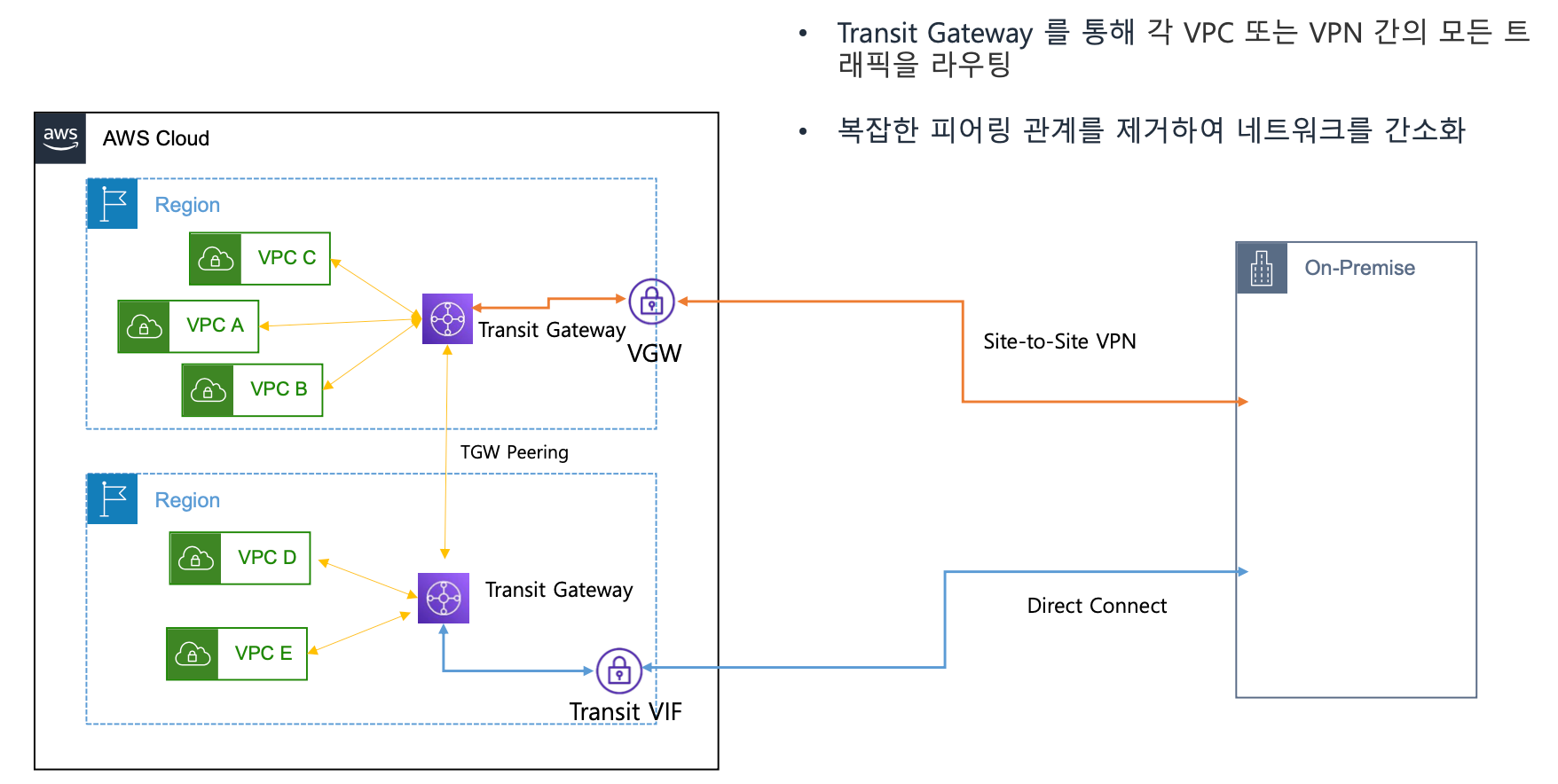
Transit Gateway (TGW)
- 모든 VPC, VPN을 중앙에서 관리
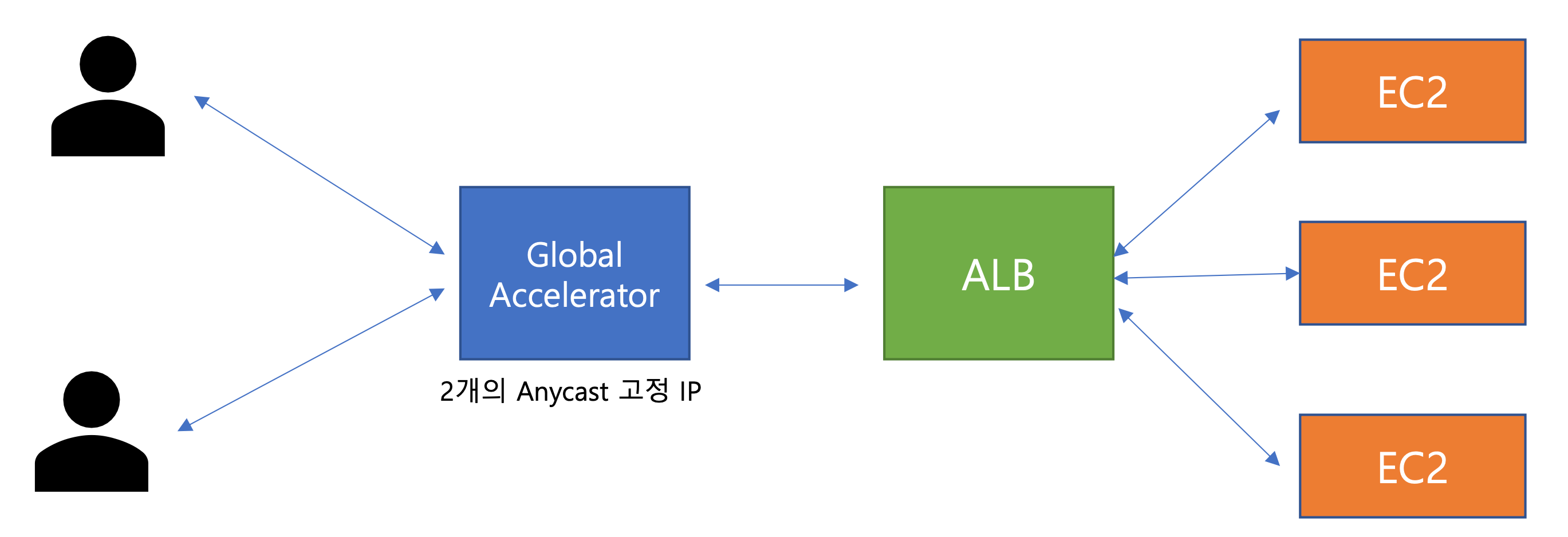
Global Accelerator #글로벌
- 글로벌 사용자의 라우팅 성능을 개선하는 솔루션
- 가장 가까운 위치(edge location)로 트래픽을 라우팅하여 인터넷 대기시간을 줄이고, 전송 성능을 향상하는 서비스
- Global Accelerator는 2개의 고정 IP를 갖는다.
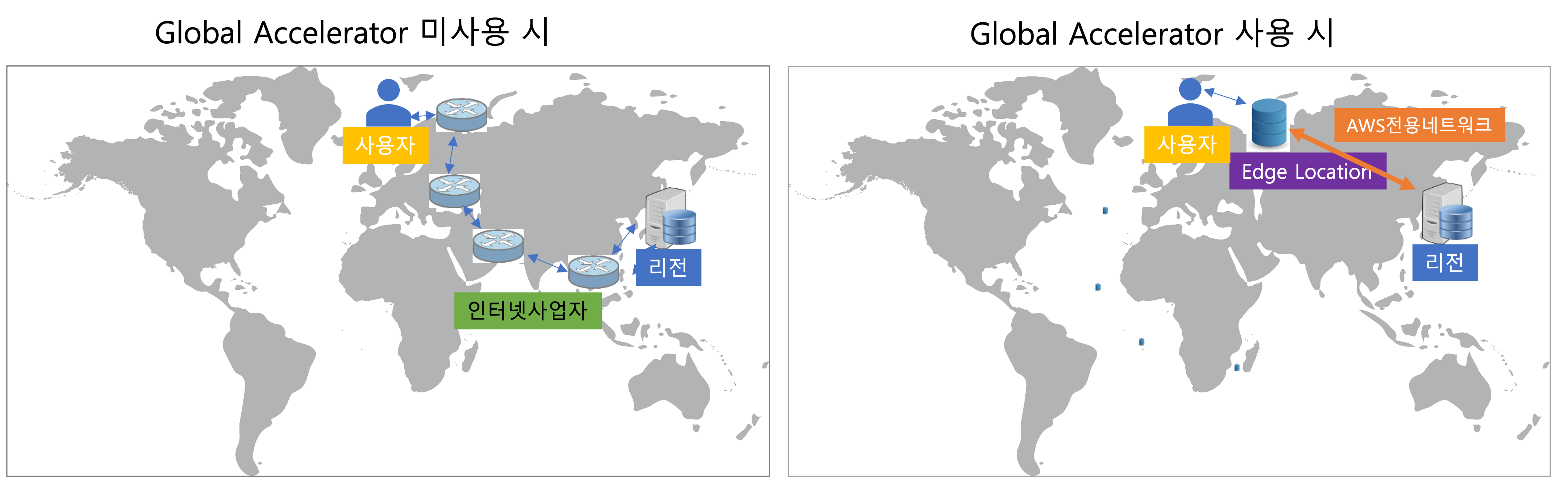
- Global Accelerator vs CloudFront Global Accelerator
변화하는 동적인 IP 주소 세트 사용 고정된 IP 주소 사용 전 세계에 분포된 엣지 로케이션 사용 전 세계에 분포된 엣지 로케이션 사용 엣지 로케이션을 콘텐츠를 캐시하는데 사용 엣지 로케이션을 가장 가까운 리전의 엔드포인트로 최적화된 경로를 찾는데 사용 HTTP 프로토콜을 처리하는데 적합 TCP, UDP 프로토콜을 처리하는데 적합 캐시 가능한 콘텐츠(예: 이미지, 비디오)와 동적인 콘텐츠(예: API 가속화 및 동적 사이트 제공)의 성능을 개선 NON-HTTP를 사용하는 게임(UDP), 미디어, VoIP, 모바일 앱, IoT 등의 다양한 애플리케이션의 성능을 향상
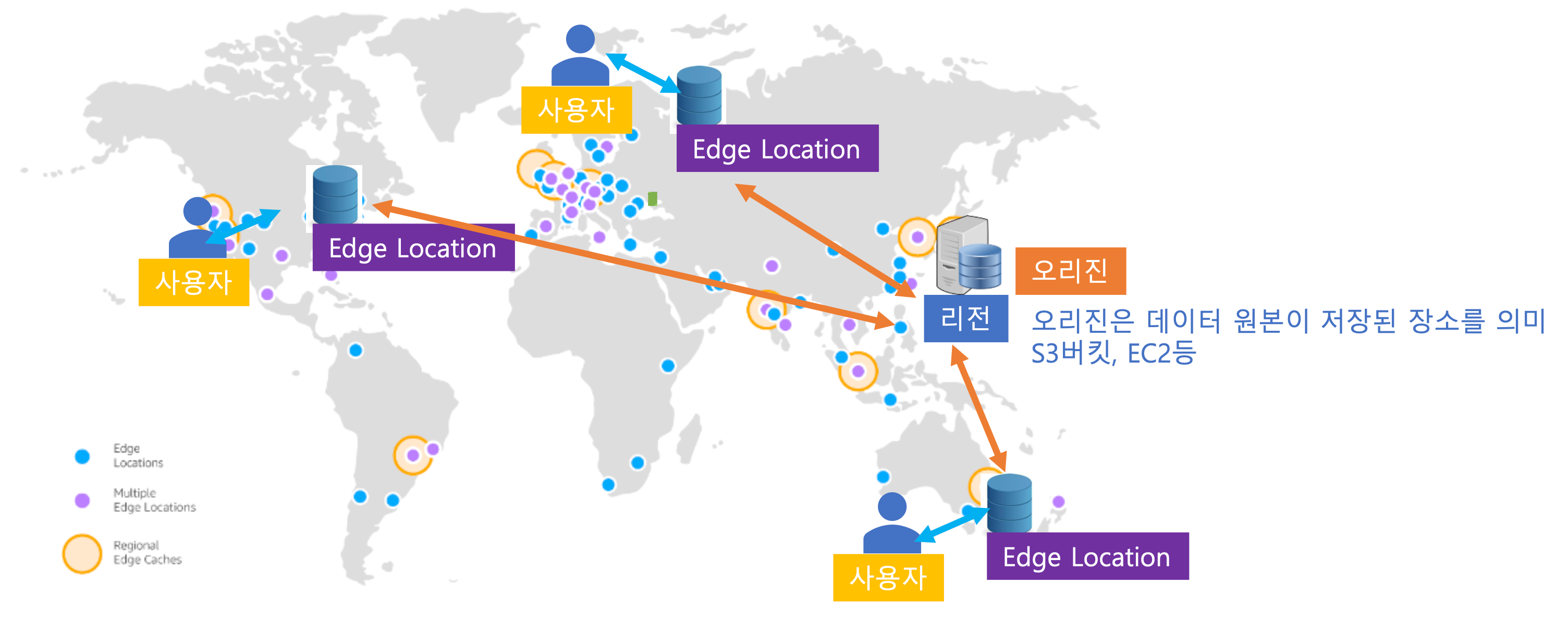
CloudFront #글로벌 #전세계사용자
- 글로벌 콘텐츠 전송 네트워크 서비스
- 엣지 로케이션에 콘텐츠 캐싱으로 트래픽 분산(사용자는 오리진까지 접속할 필요 없음)
- 엣지 로케이션의 콘텐츠 캐싱을 이용해 콘텐츠를 사용자에게 더 빨리 배포하도록 지원하는 서비스
- 엣지 로케이션은 데이터를 임시 저장할 수 있는 캐싱 기능!
- 정적(이미지 파일) 및 동적 콘텐츠(스트리밍 비디오)!
- 글로벌 사용자를 위한 웹사이트 배포 속도를 높이는 서비스
- 전 세계 수백 개의 엣지 로케이션
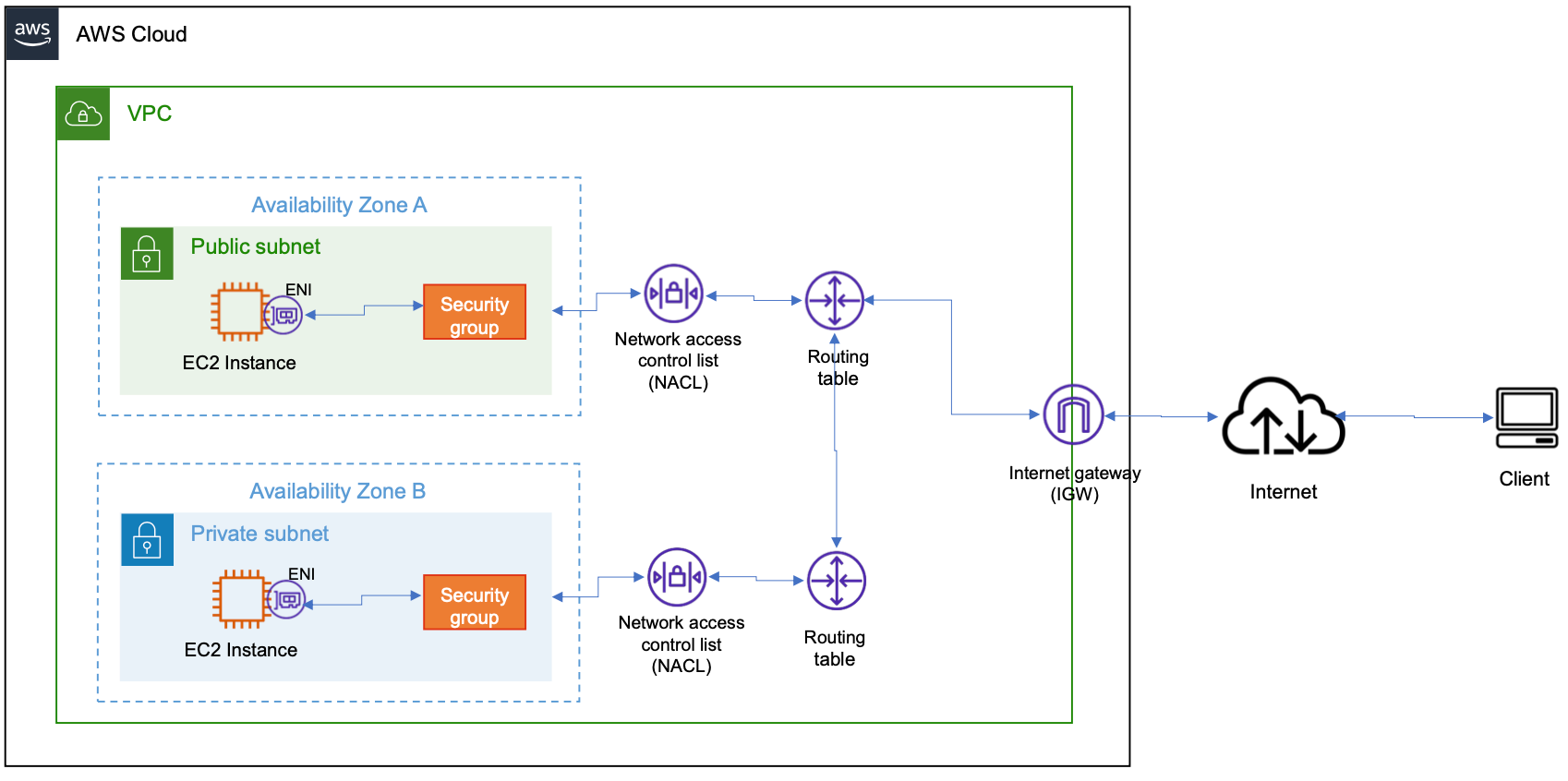
VPC (VPC Endpoint, VPC Peering)
- VPC 엔드포인트(VPC endpoint)
- VPC 엔드포인트를 통해 VPC와 S3간의 프라이빗 연결 구성
- ex1) 회사는 인터넷을 통과하지 않고, Amazon S3에 액세스하려고 합니다.
- ex2) 사내 EC2 → (VPC 엔드포인트) → 퍼블릭 S3 연결 (동일 리전)
- ex1) 웹 계층은 여러 가용 영역에 걸쳐있는 퍼블릭 서브넷이 있는 Amazon EC2 Auto Scaling 그룹을 사용하고 있습니다. 데이터베이스 계층은 별도의 프라이빗 서브넷에 있는 Amazon RDS for MySQL DB 인스턴스로 구성됩니다. 웹 계층은 제품 정보를 검색하기 위해 데이터베이스에 액세스해야 합니다... 웹 응용 프로그램에서 데이터베이스에 연결할 수 없다고 보고합니다. 네트워크 ACL에, 보안 그룹 및 라우팅 테이블에 대한 구성은 여전히 디폴트 상태에 있습니다. 솔루션 설계자는 애플리케이션을 수정하기 위해 무엇을 권장해야 합니까?
- 프라이빗 서브넷의 네트워크 ACL에 명시적 규칙을 추가하여 웹 티어의 EC2 인스턴스에서 오는 트래픽을 허용합니다. (X: 디폴트 NACL은 인바운드, 아웃바운드 트래픽 모두 허용 되어 있음)
- 웹 계층의 EC2 인스턴스와 데이터베이스 계층 간의 트래픽을 허용하도록 VPC 라우팅 테이블에 경로를 추가합니다. (X: 동일한 VPC 안의 모든 서브넷은 디폴트로 라우팅 가능)
- 데이터베이스 계층의 RDS 인스턴스 보안 그룹에 인바운드 규칙을 추가하여 웹 계층의 보안 그룹에서 오는 트래픽을 허용합니다. (정답: 디폴트 보안 그룹 인바운드 트래픽은 RDS 트래픽이 허용되어 있지 않으므로 허용 필요)
VPC 피어링 (VPC Peering)
- VPC 간에 트래픽을 라우팅할 수 있도록 네트워킹 연결
- 1:1 mapping only
Transit Gateway
- 각 VPC 또는 VPN 간의 모든 트래픽을 라우팅
- 복잡한 피어링 관계를 제거하여 네트워크를 간소화
Site-to-Site VPN
- AWS와 온프레미스 연결
Direct Connect #전용선 #안전한 연결
- AWS와 온프레미스 연결
- ex) …데이터가 민감한 것으로 간주되기 때문에 안전한 전송이 중요합니다.
- AWS Direct Connect를 통한 AWS DataSync
3. 로드 밸런싱 (Load Balancing)
NLB (Network Load Balancer)
- #고정IP #TCP/UDP
- 탄력적 IP 주소를 할당하여 고정IP 할당 가능
- TCP, UDP, TLS 요청을 로드밸런싱 해야 하는 경우에 사용
- 게임 등의 수백만의 동시 사용자 처리에 적합
- 고도의 성능이 요구되거나 대기 시간이 낮아야 하는 애플리케이션에 적합
- ALB와 다르게 리스너 규칙 설정 없음
- ex) 회사는 클라이언트와 서버 간의 통신을 위해 UDP를 사용하는 실시간 멀티플레이어 게임을 개발 중입니다…개발자는 … 되는 비관계형 데이터베이스 솔루션을 원합니다.
- 트래픽 분산에는 Network Load Balancer를 사용하고 데이터 저장에는 Amazon DynamoDB 온디맨드 사용 (정답: NLB로 UDP 트래픽 처리, DynamoDB는 비관계형 데이터 베이스 솔루션)
- 트래픽 분산에 Application Load Balancer를 사용하고 데이터 저장에 Amazon DynamoDB 글로벌 테이블 사용 (X: ALB는 HTTP 트래픽 처리 용도)
ALB (Application Load Balancer)
- 탄력적 IP 주소 할당 불가; ALB는 고정IP를 갖지 않는다!
- HTTP(S) 프로토콜을 사용하는 애플리케이션 로드 밸런싱에 사용
- 웹 애플리케이션 처리에 적합
- ALB를 VPC 외부에 배치할 수 없음
4. 보안 및 규정 준수 (Security & Compliance)
GuardDuty #위협탐지
- AWS 계정과 워크로드를 보호하는 지능형 위협 탐지 서비스
- AWS 계정 및 워크로드에서 악의적 활동 모니터링 및 상세한 보안 결과 제공
Macie #민감한데이터 #개인식별정보
- 중요한 비즈니스 크리티컬 콘텐츠를 분류하고 보호
- 기계 학습 및 패턴 일치를 활용하여 AWS에서 민감한 데이터를 검색하고 보호
- 이름, 주소 및 신용 카드 번호와 같은 개인 식별 정보(PII)를 포함하여 민감한 데이터 유형 자동 감지
- ex) … 회사는 개인 식별 정보(Pll)와 같은 민감한 정보에 대해 우려하고 있습니다… 회사는 민감한 데이터를 스캔하고 결과를 기록할 솔루션이 필요합니다.
- 정답: 수집된 데이터의 스캔을 수행하기 위해 Amazon Macie를 호출하는 일련의 AWS Lambda 함수를 생성합니다. Macie가 민감한 데이터를 찾으면 Lambda 함수를 호출하여 Amazon CloudWatch에 결과를 기록합니다. (개인 식별 정보 같은 민감한 데이터를 검색하고 보호)
Inspector #EC2 #취약성관리
- 대규모 환경에서 지속적인 취약성 관리
- EC2 및 컨테이너 워크로드에서 소프트웨어 취약성과 의도하지 않은 네트워크 노출을 지속적으로 스캔
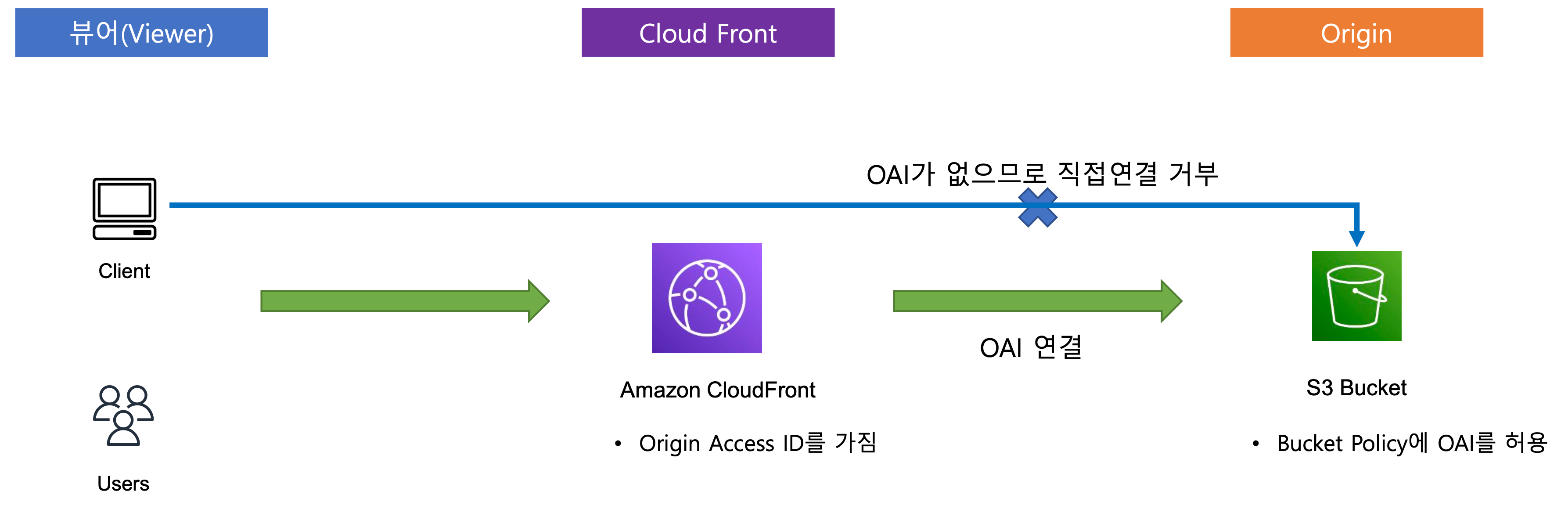
OAI (Origin Access Identity)
- OAI를 통해 S3버킷의 액세스를 클라우드 프론트를 통해서만 하도록 할 수 있게 하는 기능
WAF
- 웹 애플리케이션을 보호하는 방화벽
- 보안 그룹 생성 가능: 악성IP 차단 등
- WAF를 사용하여 특정 국가 액세스 제한 가능
- p.s. CloudFront를 이용해서 특정 국가 액세스 제한 가능
Shield
- DDoS 공격으로부터 보호
Secrets Manager #자격증명
- 자격 증명 관리 서비스, 자동 키 교체(automatic rotation)
- ↔ System Manager Parameter Store: 자동 키 교체를 지원하지 않음
- 보안 정보(자격증명)를 중앙 집중식으로 저장, 검색, 액세스 제어, 교체, 감사 및 모니터링하는 서비스
- ex1) 회사에 공통 Amazon RDS MySQL 다중 AZ DB 인스턴스에 자주 액세스해야 하는 웹 서버가 여러 대 있습니다. 회사는 사용자 자격 증명을 자주 교체해야 하는 보안 요구 사항을 충족하면서 웹 서버가 데이터베이스에 연결할 수 있는 안전한 방법을 원합니다. 이 요구 사항을 충족하는 솔루션은 무엇인가요?
- ex2) AWS Secrets Manager에 비밀번호를 저장합니다. Lambda 함수를 Secrets Manager에서 암호 ID가 지정된 암호를 검색할 수 있는 역할과 연결합니다.
ACM (AWS Certificate Manager)
- AWS에서 관리하는 인증서로 가장 비용 효율적인 솔루션 (관리자 최소 노력)
5. 메시징 및 통합 (Messaging & Integration)
SNS (Simple Notification Service)
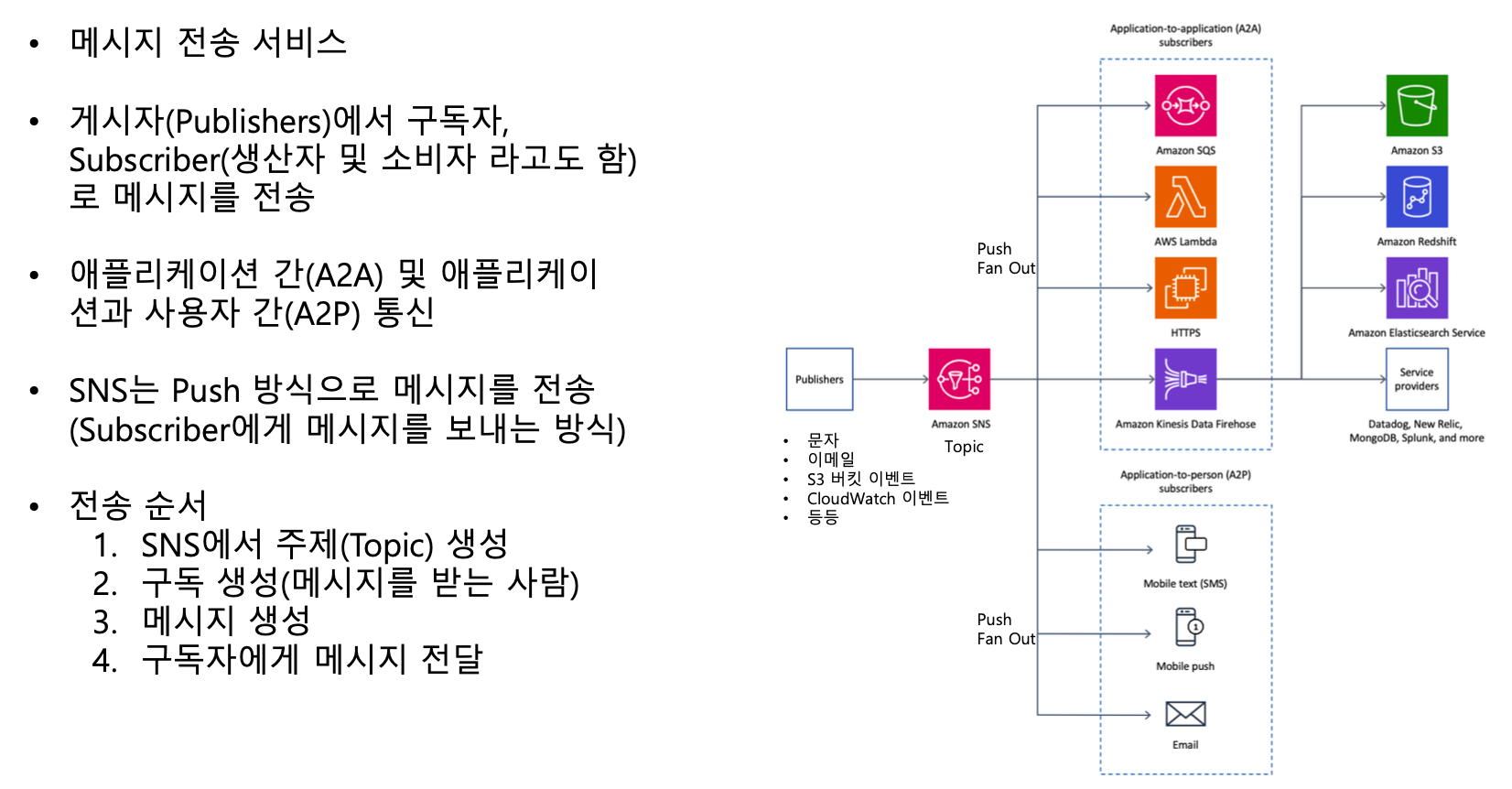
SQS (Simple Queue Service)
- SQS 대기열을 사용해 데이터 손실 방지
- 급격한 요청을 손실 없이 처리

- ex1) 이벤트 데이터를 수신하는 대로 처리하려고 합니다.
- ex2) EC2 기반, 여러 내부 서비스가 급증하는 동안 일정 기간 동안 압도되고 응답하지 않을 수 있습니다.
- SQS 사용
- EC2 인스턴스가 정상 상태일 경우, 다시 전송
- 오류를 줄이는 보다 안정적인 솔루션이 될 수 있음
- SQS 사용
- ex3) …매일 여러 번 응용 프로그램 중단을 경험했으며 결과적으로 트랜잭션 손실이 발생하였습니다. 솔루션 설계자는 애플리케이션 복원력을 개선하기 위해 무엇을 권장해야 합니까?
- Amazon Simple Queue Service(Amazon SQS)를 사용하여 인벤토리 업데이트를 전송하도록 애플리케이션 수정 (정답: 애플리케이션이 중단 되어도 SQS 대기열이 메시지를 가지고 있다가 나중에 처리하므로 트랙잭션 손실 방지 가능)
- ex4) 회사에 들어오는 메시지를 수집하는 응용 프로그램이 있습니다. 수십 개의 다른 응용 프로그램과 마이크로서비스가 이러한 메시지를 빠르게 소비합니다. 메시지 수는 급격히 줄어들고 때로는 초당 100,000개로 갑자기 증가합니다. 회사는 솔루션을 분리하고 확장성을 높이고자 합니다.
- Auto Scaling 그룹의 Amazon EC2 인스턴스에 수집 애플리케이션을 배포하여 CPU 지표를 기반으로 EC2 인스턴스 수 확장 (X: EC2로 초당 10만개의 메시지 처리 불가능)
- 여러 Amazon Simple Queue Service(Amazon SQS) 구독이 있는 Amazon Simple Notification Service(Amazon SNS) 주제에 메시지 게시 대기열의 메시지를 처리하도록 소비자 애플리케이션 구성 (정답: 애플리케이션끼리의 결합을 느슨하게 하는 솔루션은 SQS)
6. 데이터베이스 (Database)
RDS (Relational Database Service)
- 여러 데이터베이스 엔진을 선택 가능 (MySQL, PostgreSQL, Oracle, SQL Server 등)
- 기존 데이터베이스 엔진을 그대로 호스팅하는 서비스 완전관리형 DB 서비스
- 백업, 패치, 모니터링 등 기본적인 관리 작업을 AWS가 처리
Aurora
- MySQL 및 PostgreSQL과 호환되는 클라우드 기반 관계형 데이터베이스
- 기존 데이터베이스 대비 최대 5배의 성능 제공 및 자동 확장과 고가용성 지원
- ex1) 회사는 Amazon Aurora에서 데이터베이스를 실행 중입니다. … 트래픽이 급증하는 아침 시간에 성능 문제를 경험합니다. 이러한 피크 기간 동안 데이터베이스에서 읽을 때 애플리케이션이 시간 초과 오류를 수신합니다. 회사에는 전담 운영 팀이 없고 성능 문제를 해결하기 위한 자동화된 솔루션이 필요합니다.
- 정답1: 데이터베이스를 Aurora Serverless로 마이그레이션
- 정답2: Aurora 복제본으로 Aurora Auto Scaling을 구성합니다. (읽기 로드를 자동으로 조정)
MySQL 다중 AZ 배포용 Amazon RDS로 데이터베이스 마이그레이션- RDS 다중 AZ 배포는 읽기로드 자동 조정이 목적이 아닌 가용성 확장이 목적
DynamoDB
- No-SQL
- Serverless, 밀리초 응답을 제공하는 대기 시간이 짧은 DB 필요에 적합
ElastiCache
- 인메모리 데이터 스토어
- 반복되는 요청을 캐시에 저장하여 응답속도를 빠르게 하기 위한 기능
- ex) 성능 저하를 일으키는 데이터베이스에서 동일한 데이터베이스를 반환하라는 호출이 자주 있습니다.
7. 분석 및 빅데이터 (Analytics & Big Data)
Kinesis (Data Streams, Video Streams, Data Firehose, Data Analytics) #실시간
- 실시간 스트리밍 데이터 수집, 처리 및 분석 서비스
- 데이터를 수신 순서대로 처리할 수 있음
- 비디오, 오디오, 애플리케이션 로그, 웹 사이트 클릭스트림 및 IoT 텔레메트리 데이터와 같은 실시간 데이 터를 수집
- 실시간 클릭스트림 데이터를 처리하기에 적합한 솔루션
- Kinesis Data Streams: 데이터 스트림을 수집, 저장 및 처리
- Kinesis Data Streams 에서는 바로 S3로 데이터를 전송할 수 없다: Kinesis Data Streams Host를 이용해야 함
- Kinesis Video Streams: 비디오 스트림을 수집, 저장 및 처리
- Kinesis Data Firehose: 데이터 스트림을 AWS 데이터 스토어에 로드
- Kinesis Data Analytics: Apache Flink로 데이터 스트림 분석
Athena #쿼리
- 서버리스 대화형 분석 서비스
- 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 분석할 수 있는 쿼리 서비스
- EMR(Elastic MapReduce)
- 빅데이터 플랫폼; Hadoop 클러스터를 손쉽게 생성해주는 서비스
- 머신러닝, 빅데이터 처리 등에 사용
Redshift #복잡한분석쿼리
- 데이터웨어하우스: 의사 결정을 위한 정보의 집합
- SQL 쿼리 및 BI 도구 액세스
- 대량의 데이터를 중앙 집중화 및 통합 > 데이터 웨어하우스 분석 기능 > 의사결정을 개선
- ex) …매주 총 70GB의 데이터가 생성되며 회사는 이력 보고를 위해 3년 동안의 데이터를 저장해야 합니다. 회사는 가장 짧은 시간에 복잡한 분석 쿼리 및 조인을 수행하여 Amazon S3에서 집계를 처리하고 데이터를 보강해야 합니다. 집계된 데이터 세트는 Amazon QuickSight 대시보드에서 시각화됩니다.
- AWS Glue에서 ETL 작업을 생성 및 실행하여 Amazon S3의 데이터를 처리하고 Amazon Redshift로 로드 Amazon Redshift에서 집계 쿼리 수행
- (정답: 복잡한 분석 쿼리 및 조인을 수행하는 솔루션은 데이터 웨어하우스인 Redshift 이용)
8. 컴퓨팅 (Compute)
EC2
- 가장 기본적인 AWS 컴퓨팅 서비스
- 필요에 따라 용량 조정 가능 (Auto Scaling)
- 온디맨드, 예약, 스팟 등 다양한 요금 옵션
- 실무에서는 Lambda(서버리스)와 비교되는 경우가 많음
Lambda
- 최대 15분까지 실행 가능. 따라서 장기 실행 프로세스에는 적합하지 않음
9. 데이터 마이그레이션 및 전송
- DataSync #NFS지원
- 온프레미스 스토리지 ↔ AWS 스토리지 데이터 마이그레이션을 자동화하는 서비스
- 변경 사항 발생 즉시 콘텐츠 반환하는 강력한 일관성 지원 불가 (↔ EFS;Elastic File System)
- 완전 관리형 솔루션: 스냅샷을 복제할 필요 없으며, 온프레미스 데이터를 바로 S3로 마이그레이션 가능
- 무결성 확인 및 암호화 제공
- Snow Family
- 대용량의 온프레미스에 있는 데이터를 AWS로 마이그레이션 해야할 때 사용
- snowcone: ~8T
- snowball: 수십TB 이상
- snowmobile: PB 이상
- 대용량의 온프레미스에 있는 데이터를 AWS로 마이그레이션 해야할 때 사용
10. 관리 및 거버넌스
CloudTrail
- 사용자 활동 및 API 사용 추적
- AWS 계정이 수행하는 작업(사용자, 역할 또는 AWS 서비스가 수행하는 작업)을 CloudTrail에 이벤트(로그)로 기록하는 서비스
Trusted Advisor
- 성능 및 보안 최적화
- AWS 모범 사례에 대한 권장 사항을 제공하는 서비스
Config
- AWS는 리소스 구성 변경 사항에 대한 로그를 기록하는 서비스
Elastic Beanstalk #최소운영오버헤드 #관리형솔루션 #고가용성
- 웹 애플리케이션 및 서비스를 배포하고 운영하는 서비스
- 코드만 업로드하면 AWS에서 알아서 구성 ㅇㅇ
- 사용자가 직접 인프라 리소스를 구성할 필요 없고, 애플리케이션 코드에만 집중하면 됨
- ex1)
- 특정시간에 트래픽 증가로 응답시간 느려짐 > 최소한의 구성으로 문제해결해야 함
- Elastic Beanstalk > 부하 기반 auto scaling 및 시간 기반 조정 구성
- ex2)
- (정답) 웹 애플리케이션을 AWS Elastic Beanstalk 환경에 배포. URL 스와핑을 사용하여 기능 테스트를 위해 여러 Elastic Beanstalk 환경 간 전환
함정 주의
- Lambda는 최대 실행 시간이 15분!
- 여러 AWS 리전에서 온라인으로 사용할 수 있는 솔루션이 필요합니다.
- ~~다중 AZ 기능이 켜진 상태에서 …~~
- 질문의 여러 리전에서 온라인으로 사용 요구사항에 맞지 않음
- ~~다중 AZ 기능이 켜진 상태에서 …~~
- 관리 오버헤드 최소화
- 완전 관리형 서비스, Serverless 서비스
- ⚠️ EC2는 관리 오버헤드를 최소화하는 방법이 아님
- 고가용성
- 가용성: 시스템이 정상적으로 사용 가능한 정도
- 서로 다른 가용 영역에 프로비저닝
- 트래픽
- ALB + Auto Scaling
- 웹 애플리케이션(HTTP)에 적합. 여러 가용영역의 ALB 배포로 고가용성 설계
- Auto Scaling으로 높은 트래픽과 내결함성 지원
- Auto Scaling의 한계점: 급격한 트래픽 처리를 위한 최적의 솔루션이 될 수는 없음 → 확장하는데 시간 소요
- ⚠️
클러스터 배치그룹: 동일 가용 영역 내의 배치로 고가용성을 높이는 솔루션이 아니다
- ALB + Auto Scaling
- AD(Active Directory) 인증
- S3는 AD 인증을 지원하지 않음
- S3는 파일 공유 스토리지 솔루션이 아님, AD 통합 불가
- SCP(Service Control Policy; 서비스 제어 정책)
- ex1) 회사의 보안 정책에 따라 정기적인 감사를 위해 AWS 계정의 모든 AWS API 활동을 기록해야 합니다. 회사는 AWS Organizations를 사용하여 현재 . 및미래의 모든 AWS 계정에서 AWS CloudTrail을 활성화해야 합니다.
- 조직의 루트 아래에 있는 모든 기존 계정 추가 사용자가 CloudTrail을 비활성화하지 못하도록하는 모든 계정에 서비스 제어 정책(SCP)을 정의하고 연결합니다.
- ex1) 회사의 보안 정책에 따라 정기적인 감사를 위해 AWS 계정의 모든 AWS API 활동을 기록해야 합니다. 회사는 AWS Organizations를 사용하여 현재 . 및미래의 모든 AWS 계정에서 AWS CloudTrail을 활성화해야 합니다.
- 글로벌 데이터베이스(Global Database)
- 회사는 다중 지역 재난 복구 RPO(Recovery Point Objective)가 1초이고, RTO(Recovery Time Objective)가 1분인 관계형 데이터베이스를 구현해야 합니다.
- RPO 1초: 1초 미만 대기시간으로 5개 보조 리전에 복제
- RTO 1분: 보조 리전 중 하나가 1분 이내 읽기/쓰기 기능으로 승격
- 글로벌 테이블(Global Table)
- 리전 간의 데이터 베이스 복제 기능
- 보안 그룹은 차단 설정이 없다!
- NAT GW는 IPv4 주소만 라우팅 가능
- 동일한 가용영역 내의 EC2 간의 데이터 전송 비용 무료
- ex1) 회사에서 Amazon EC2 인스턴스에서 실행되는 지연 시간에 민감한 애플리케이션을 위해 인메모리 데이터베이스를 실행하려고 합니다. 이 애플리케이션은 분당 100,000건 이상의 트랜잭션을 처리하며 높은 네트워크 처리량이 필요합니다. 솔루션 설계자는 데이터 전송 비용을 최소화 하는 비용 효율적인 네트워크 설계를 제공해야 합니다. 어떤 솔루션이 이러한 요구 사항을 충족합니까?
- 정답: 동일한 AWS 리전 내의 동일한 가용 영역에서 모든 EC2 인스턴스를 시작합니다. EC2 인스턴스를 시작할 때 클러스터 전략으로 배치 그룹을 지정하십시오. (클러스터 배치그룹으로 높은 네트워트 처리량 설계 및 동일 가용영역 내의 EC2 간의 데이터 전송 비용 무료)
- 오답: Auto Scaling 그룹을 배포하여 네트워크 사용률 목표에 따라 다른 가용 영역에서 EC2 인스턴스를 시작합니다. (서로 다른 가용영역의 EC2 데이터 전송 비용은 유료)
- ex2) 대용량 데이터의 일괄 처리를 처리할 애플리케이션을 만들고 있습니다. 입력 데이터는 Amazon S3에 저장되고, 출력 데이터는 다른 S3 버킷에 저장됩니다. 처리를 위해 애플리케이션은 네트워크를 통해 데이터를 전송합니다. 여러 Amazon EC2 인스턴스 간 전체 데이터 전송 비용을 줄이기 위해 솔루션 설계자는 무엇을 해야 합니까?
- 모든 EC2 인스턴스를 동일한 가용 영역에 배치 (정답 : 동일 가용 영역 내의 EC2 간의 데이터 전송 비용 무료)
- ex1) 회사에서 Amazon EC2 인스턴스에서 실행되는 지연 시간에 민감한 애플리케이션을 위해 인메모리 데이터베이스를 실행하려고 합니다. 이 애플리케이션은 분당 100,000건 이상의 트랜잭션을 처리하며 높은 네트워크 처리량이 필요합니다. 솔루션 설계자는 데이터 전송 비용을 최소화 하는 비용 효율적인 네트워크 설계를 제공해야 합니다. 어떤 솔루션이 이러한 요구 사항을 충족합니까?




댓글