본문
[AWS Rekognition] 이미지 분석 실습
AWS/실습 2025. 12. 18. 19:39
반응형
AWS Rekognition은 Amazon Web Services가 제공하는 이미지 및 동영상 분석 서비스입니다. 머신 러닝 기술을 활용하여 객체, 장면, 얼굴, 텍스트 등을 감지하고 인식할 수 있습니다. 이 글에서는 AWS Rekognition의 주요 기능과 활용 방법에 대해 알아보겠습니다.
1. 이미지 분석
1.1. 객체 및 장면 감지
- Rekognition은 이미지 내의 객체와 장면을 감지하고 분류할 수 있습니다.
- 수천 가지의 객체와 장면을 인식할 수 있으며, 각 객체의 위치와 신뢰도 점수를 제공합니다.
- 예시: 제품 이미지 분석, 자율 주행 차량의 환경 인식 등
1.2. 얼굴 감지 및 분석


- 이미지에서 얼굴을 감지하고, 각 얼굴의 속성(나이, 감정, 시선 등)을 분석할 수 있습니다.
- 얼굴 비교 기능을 통해 두 얼굴이 동일한 사람인지 여부를 판단할 수 있습니다.
- 얼굴 모음(Face Collection)을 생성하여 대규모 얼굴 인식 및 검색이 가능합니다.
- 예시: 사용자 인증, 출입 관리, 감정 분석 등
1.3. 텍스트 감지 (OCR)
- 이미지 내의 텍스트를 감지하고 추출할 수 있습니다.
- 인쇄된 텍스트뿐만 아니라 손글씨도 인식 가능합니다.
- 다양한 언어를 지원하며, 텍스트의 위치와 신뢰도 점수를 제공합니다.
- 예시: 명함 정보 추출, 차량 번호판 인식, 문서 디지털화 등
2. 동영상 분석
2.1. 얼굴 감지 및 인식
- 동영상에서 얼굴을 감지하고 추적할 수 있습니다.
- 등록된 Face Collection과 비교하여 동영상 내의 인물을 식별할 수 있습니다.
- 예시: 영상 내 인물 검색, CCTV 영상 분석 등
2.2. 객체 및 활동 감지

- 동영상 내의 객체를 감지하고 추적할 수 있습니다.
- 사람, 차량, 동물 등 다양한 객체를 인식하며, 각 객체의 이동 경로를 추적합니다.
- 특정 활동(걷기, 뛰기, 싸움 등)을 감지할 수 있습니다.
- 예시: 교통량 분석, 이상 행동 탐지, 스포츠 경기 분석 등
2.3. 유해 콘텐츠 감지
- 동영상에서 유해하거나 부적절한 콘텐츠를 감지할 수 있습니다.
- 성인 콘텐츠, 폭력적인 장면, 불법 활동 등을 식별하여 필터링할 수 있습니다.
- 예시: 동영상 플랫폼의 콘텐츠 모더레이션, 온라인 게시물 감시 등
3. Rekognition Custom Labels

- Rekognition Custom Labels는 사용자 지정 머신 러닝 모델을 생성할 수 있는 기능입니다.
- 고객이 직접 이미지 데이터셋을 업로드하고 레이블을 지정하여 맞춤형 모델을 학습시킬 수 있습니다.
- 산업별, 도메인별 특화된 객체 감지 모델을 만들 수 있습니다.
- 예시: 제조업에서 제품 검사, 농업에서 작물 모니터링, 의료 영상 진단 등
4. Rekognition과 다른 AWS 서비스 연계

- S3: 분석할 이미지와 동영상을 S3 버킷에 저장하고, Rekognition API를 호출하여 분석을 수행합니다.
- Lambda: Rekognition 분석 결과를 기반으로 Lambda 함수를 트리거하여 후처리 작업을 자동화할 수 있습니다.
- Kinesis Video Streams: 실시간 비디오 스트림을 Rekognition으로 분석하여 실시간 객체 감지, 얼굴 인식 등을 수행할 수 있습니다.
정리
AWS Rekognition은 강력한 이미지 및 동영상 분석 기능을 제공하여 다양한 비즈니스 문제를 해결할 수 있습니다. 객체 감지, 얼굴 인식, 텍스트 추출 등의 기능을 활용하면 이미지와 동영상에서 유용한 정보를 추출하고 인사이트를 얻을 수 있습니다. 또한, Rekognition Custom Labels를 통해 도메인 특화 모델을 만들어 고객별 요구사항에 맞는 분석 서비스를 제공할 수 있습니다. AWS의 다른 서비스와 연계하여 Rekognition을 활용한다면 더욱 강력하고 자동화된 분석 파이프라인을 구축할 수 있습니다.
Rekognition을 활용한 Object Detection 실습
본 실습에서는 Amazon Rekognition을 활용하여 이미지 속에서 객체를 검출하는 내용을 다룹니다. Amazon Rekognition 을 활용하면 API수준에서 쉽게 이미지 속의 오브젝트를 검출할 수 있습니다.
1. 샘플이미지 로드
1.1. 샘플이미지는 다음을 활용하겠습니다.

1.2. 필요 라이브러리 Import
import boto3
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
1.3. 이미지 확인
image_path = 'sample.jpg'
image = Image.open(image_path)
plt.figure(figsize=(15, 15))
plt.imshow(image)
plt.axis('off')
plt.show()
import boto3
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image

1.4. AWS Python SDK인 Boto3를 활용하여 클라이언트 초기화
- 자격증명이 이미 구성되어있는경우 Default 프로필을 사용하여 진행합니다.
rekognition = boto3.client('rekognition')
- 자격증명 구성이 존재하지 않는경우 aws_access_key_id 와 aws_secret_access_key 를 직접 전달합니다.
aws_access_key_id = "AKIA...."
aws_secret_access_key = "Zp...."
rekognition = boto3.client('rekognition',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,)
1.5. 최대로 감지할 라벨 갯수와 최소 컨피던스를 설정하여 API 콜 합니다.
- MaxLabels : 최대 감지할 라벨 수를 설정합니다.
- MinConfidence : 최소 컨피던스입니다. 이를 초과하는 경우 검출됩니다.
# 최대로 감지할 라벨
max_labels=10
# 최소 컨피던스 (threshold, 초과 시 검출됨)
min_confidence=95
with open(image_path, 'rb') as image_file:
image_bytes = image_file.read()
response = rekognition.detect_labels(
Image={'Bytes': image_bytes},
MaxLabels=max_labels,
MinConfidence=min_confidence
)
1.6. Response를 확인해보겠습니다.
response['Labels']
[{'Name': 'Pedestrian',
'Confidence': 99.9852523803711,
'Instances': [],
'Parents': [{'Name': 'Person'}],
'Aliases': [],
'Categories': [{'Name': 'Person Description'}]},
{'Name': 'Person',
'Confidence': 99.9852523803711,
'Instances': [{'BoundingBox': {'Width': 0.12218771129846573,
'Height': 0.5296525955200195,
'Left': 0.5033873319625854,
'Top': 0.3425632119178772},
'Confidence': 98.49806213378906},
{'BoundingBox': {'Width': 0.06897973269224167,
'Height': 0.5191138386726379,
'Left': 0.9307627081871033,
'Top': 0.35653653740882874},
'Confidence': 98.43036651611328},
{'BoundingBox': {'Width': 0.09470358490943909,
'Height': 0.5733098983764648,
'Left': 0.3799506723880768,
'Top': 0.37358373403549194},
'Confidence': 98.38298034667969},
{'BoundingBox': {'Width': 0.2699248194694519,
'Height': 0.9478078484535217,
...
'Top': 0.4051380157470703},
'Confidence': 96.77462005615234}],
'Parents': [{'Name': 'Adult'}, {'Name': 'Male'}, {'Name': 'Person'}],
'Aliases': [],
'Categories': [{'Name': 'Person Description'}]}]
- Amazon Rekognition의 response['Labels']는 이미지에서 감지된 레이블(label)들의 리스트를 담고 있는 구조입니다. 각 레이블은 이미지에서 인식된 객체, 장면, 활동 등을 나타냅니다.
- response['Labels']의 각 요소는 다음과 같은 정보를 포함하는 딕셔너리입니다:
- Name: 감지된 레이블의 이름을 나타내는 문자열입니다. 예를 들어, "Person", "Car", "Landscape" 등이 될 수 있습니다.
- Confidence: 레이블이 정확하게 감지되었다고 확신하는 정도를 나타내는 0에서 100 사이의 실수 값입니다. 값이 높을수록 레이블 감지에 대한 확신도가 높음을 의미합니다.
- Instances: 감지된 레이블의 인스턴스 정보를 담은 리스트입니다. 각 인스턴스는 이미지 내에서 해당 레이블이 감지된 특정 영역을 나타냅니다. 인스턴스 정보에는 BoundingBox (감지된 영역의 위치와 크기), Confidence (인스턴스 감지에 대한 확신도) 등이 포함됩니다.
- Parents: 감지된 레이블의 상위 레이블 정보를 담은 리스트입니다. 예를 들어, "Car"라는 레이블의 상위 레이블로는 "Vehicle"이 있을 수 있습니다.
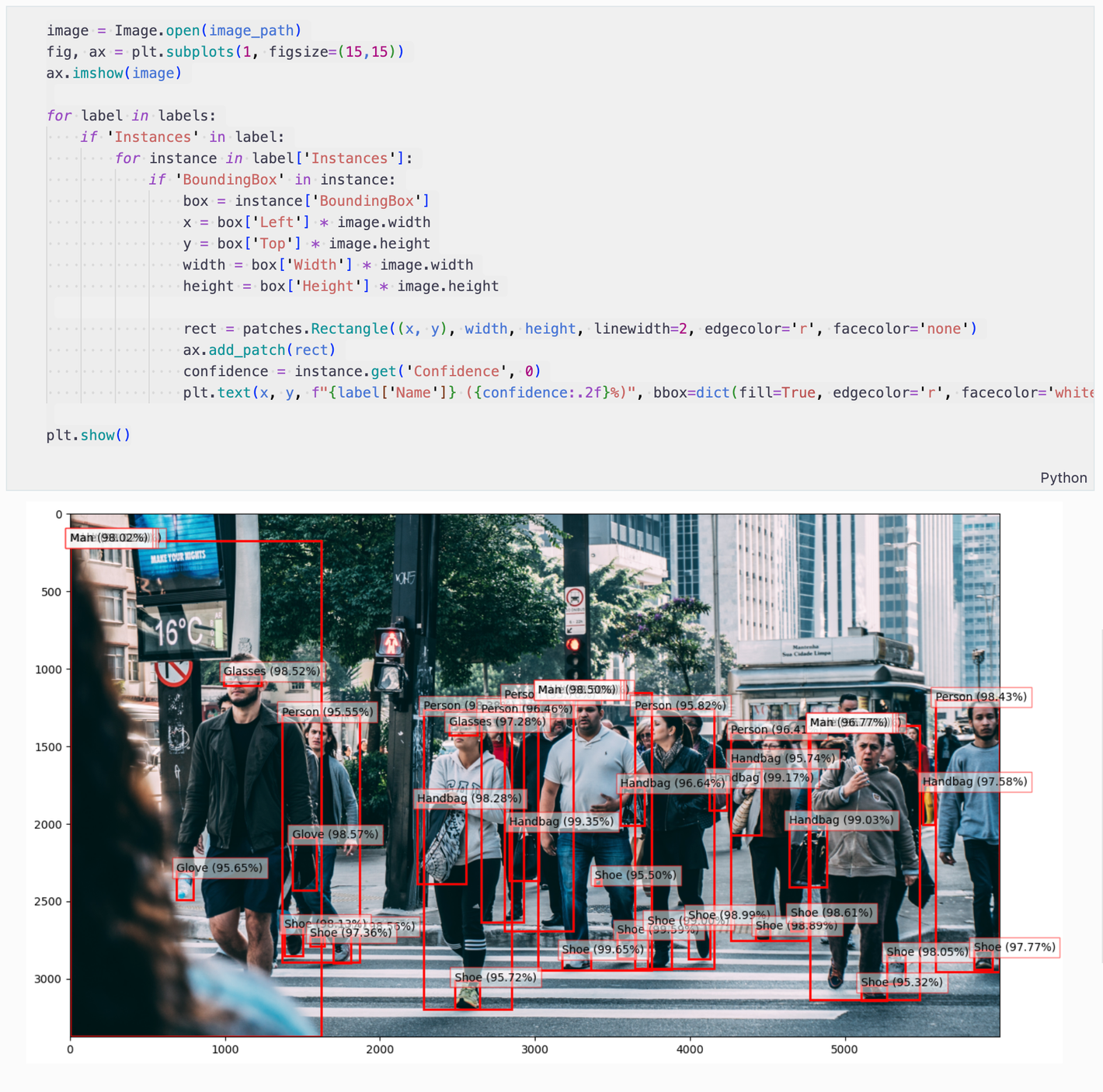
1.7. 바운딩 박스를 생성하고 출력해보겠습니다.
image = Image.open(image_path)
fig, ax = plt.subplots(1, figsize=(15,15))
ax.imshow(image)
for label in labels:
if 'Instances' in label:
for instance in label['Instances']:
if 'BoundingBox' in instance:
box = instance['BoundingBox']
x = box['Left'] * image.width
y = box['Top'] * image.height
width = box['Width'] * image.width
height = box['Height'] * image.height
rect = patches.Rectangle((x, y), width, height, linewidth=2, edgecolor='r', facecolor='none')
ax.add_patch(rect)
confidence = instance.get('Confidence', 0)
plt.text(x, y, f"{label['Name']} ({confidence:.2f}%)", bbox=dict(fill=True, edgecolor='r', facecolor='white', alpha=0.5))
plt.show()
반응형




댓글